Over the last year, I’ve been working on a new Ruby application server called Pitchfork. In most regards it’s extremely similar to the venerable Unicorn, from which it originates, but with one major extra feature: Reforking, which reduce memory usage of Ruby applications.
For most of last year, we couldn’t enable reforking on our application because of an incompatibility with one of our dependencies, but since then the issue has been solved and we’ve been rolling out reforking progressively since late July.
In this post I’m sharing some metrics from Shopify’s monolith during the final week before we fully enabled reforking. During that time half of our servers had reforking enabled.
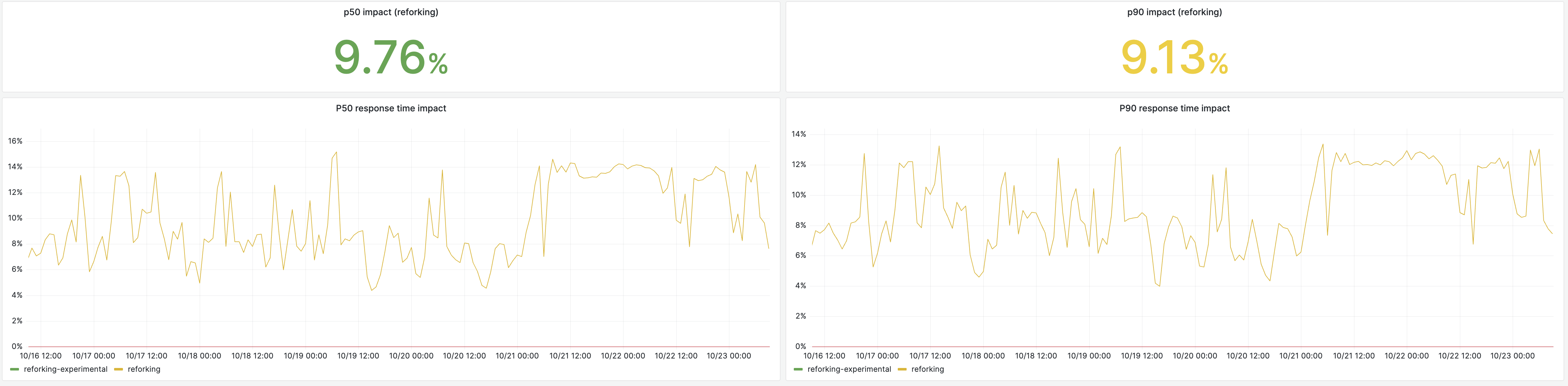
We witnessed a ~9% latency reduction across the board. Up to 14% during periods where the application is not frequently deployed (e.g. weekends):
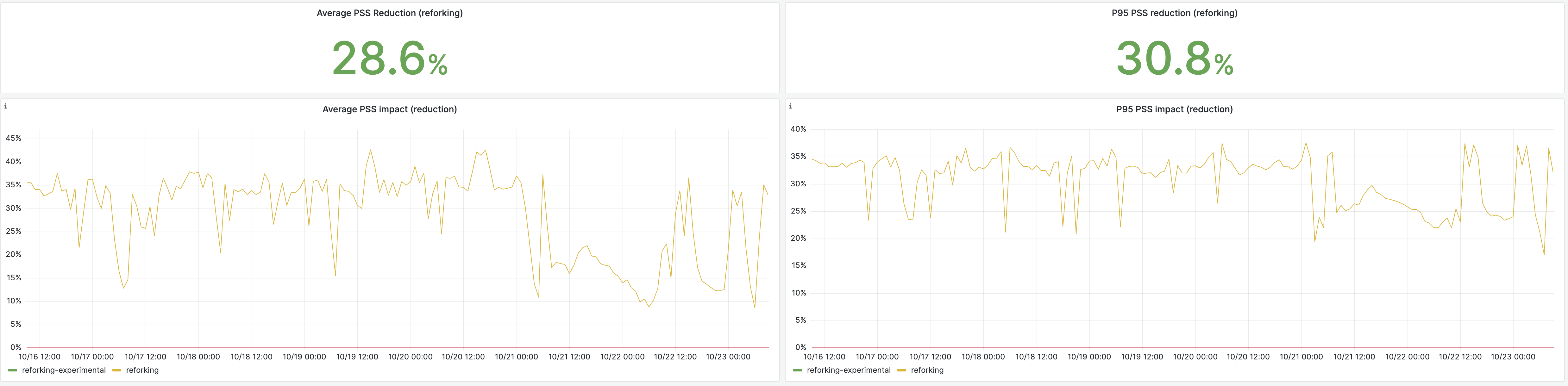
In memory usage, the reduction is roughly 30%, but only 10-12% during weekends when the application is infrequently deployed.
These are just the headline metrics, and some may be counterintuitive, most need a lot of context to be understood properly, so I need to dive in a bit on a few lower-level metrics to explain them.
We configured Pitchfork to refork up to 20 times:
export PITCHFORK_REFORK_AFTER="500,750,1000,1200,1400,1800,2000,2200,2400,2600,2800,3000,3200,3400,3600,3800,4000,4200,4400,4600,|"
This list is the number of requests a worker must process to be promoted as the mold for the next generation. Each generation takes progressively longer to be spawned, the reasoning is that a freshly booted app has a lot of not-yet initialized memory regions, but as the process ages, more and more of these regions are initialized, reducing the benefits of reforking.
On a normal day, Shopify’s monolith is deployed more or less every 30 minutes, as a result, Pitchfork only reaches its final generation when developers are not actively shipping features, so for a few hours every night, and on the weekends:
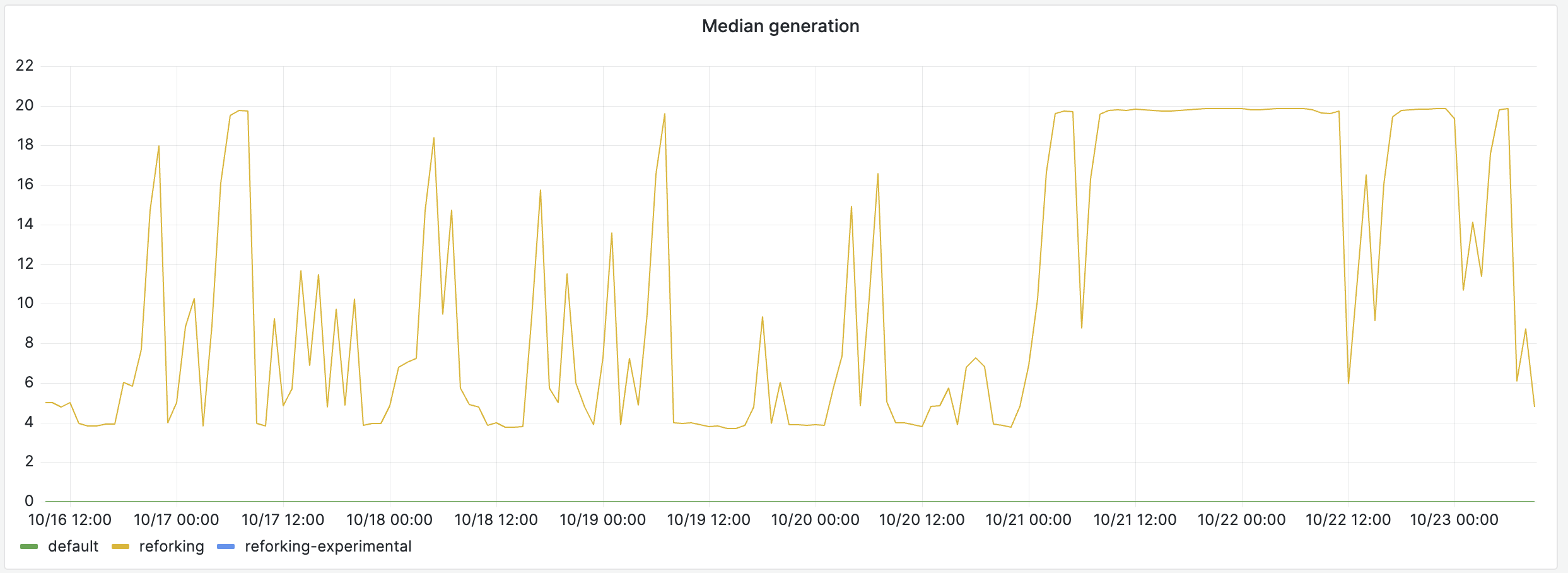
That’s why the latency improvements are better over these periods, the longer Pitchfork can run, the more benefits it can bring.
I need to explain this as it is counterintuitive. Reforking itself actually degrades latency. When a process is forked, all the memory pages are shared, which means when the new child writes into a memory region, the kernel has to stop the process and copy the memory page over, this is a very costly operation. This means that reforking is a direct tradeoff between memory usage and latency. The more often you refork, the more you increase your application latency, and the more you reduce its memory usage.
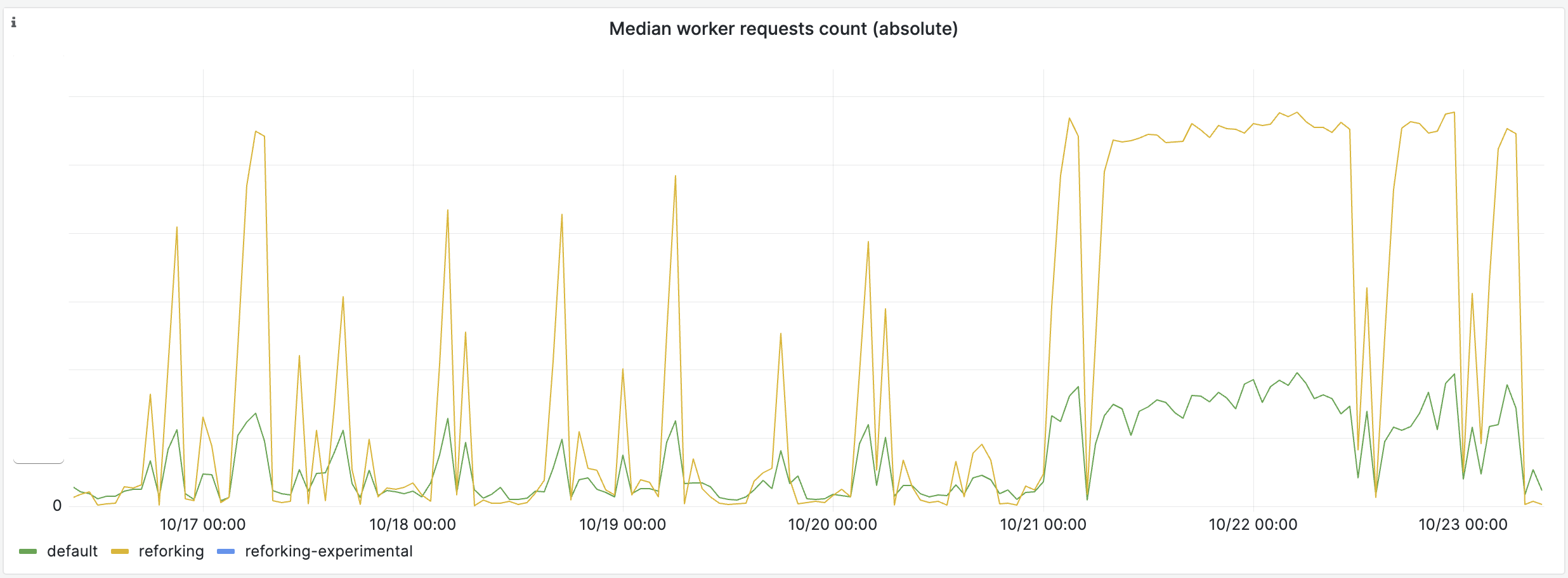
However, in Shopify’s monolith case, reforking does improve latency because it increases the “warmness” of the average worker.
First, every time we refork we replace all workers with a copy of the most warmed-up worker, this means on average reforking improves things like inline cache hits, JITed code, etc.
This has many beneficial side effects. For instance, reforked workers have much more JITed code than non-reforked workers
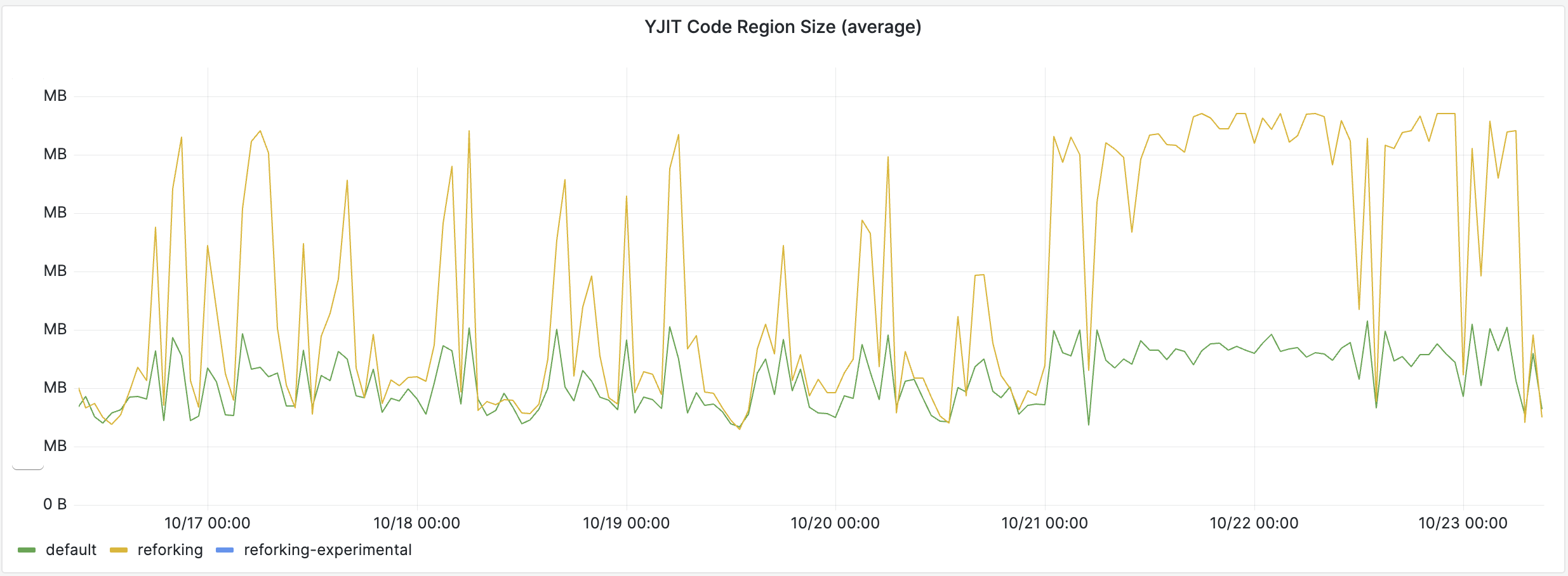
And the average “warmness” of workers is doubly improved by reforking thanks to the memory usage reduction. Since we enabled YJIT, our web workers were a bit memory-constrained and were hitting the memory limit more frequently than they used to:
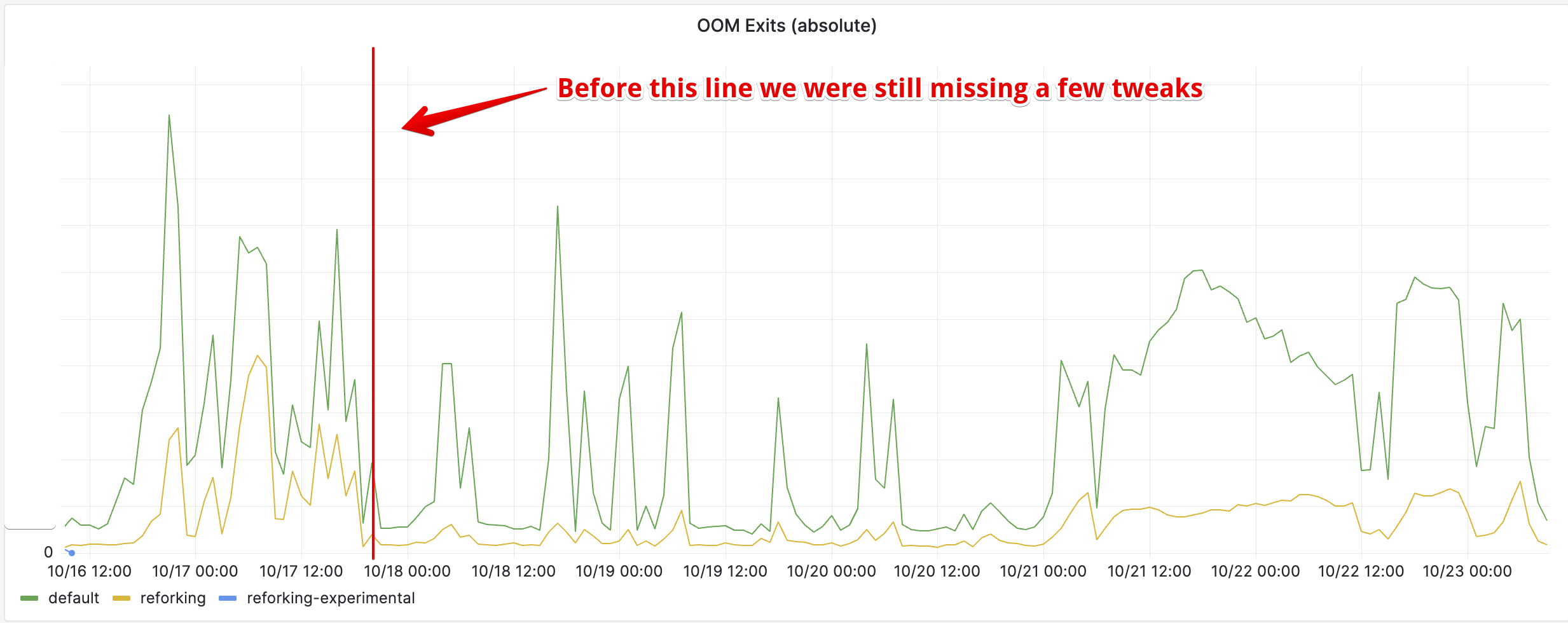
This reduction of the memory usage of the application had the knock-on effect of reducing OOM exits, which directly impacted the average warmness of workers. Whenever a worker exits because of the OOM limit or of a timeout, it is replaced by a freshly spawned worker. Without reforking this means a cold worker, that has to fill its caches and compile JITed code from scratch. With reforking we directly respawn a warm worker.
So effectively, the memory usage reduction is more than what the initial memory graph shows. If it wasn’t for the memory limit we impose on our workers, they would have used even more memory.
The main idea behind reforking is to increase the amount of memory shared by Copy-on-Write, and that can directly be witnessed in production:
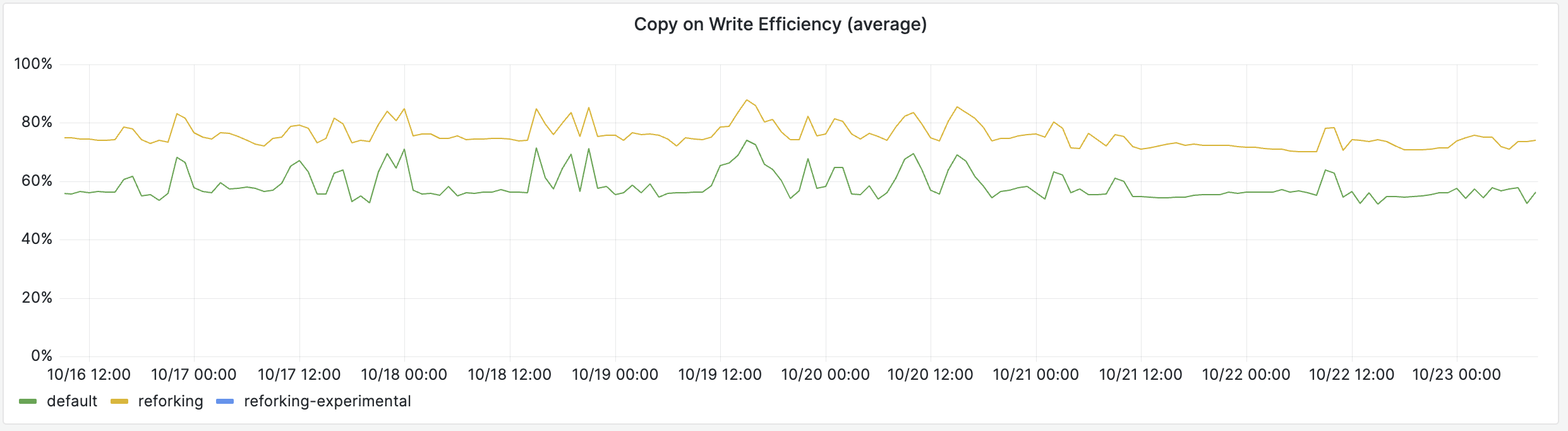
A much larger portion of the workers’ memory is shared with other processes, so the real memory usage is much lower. Our production pods run 36 Pitchfork workers, so for instance, if you were to allocate 128MiB to YJIT, without reforking it would require 4.6GiB of extra RAM for the whole pod, but with reforking most of that memory is shared and only requires marginally more than 128MiB of RAM.
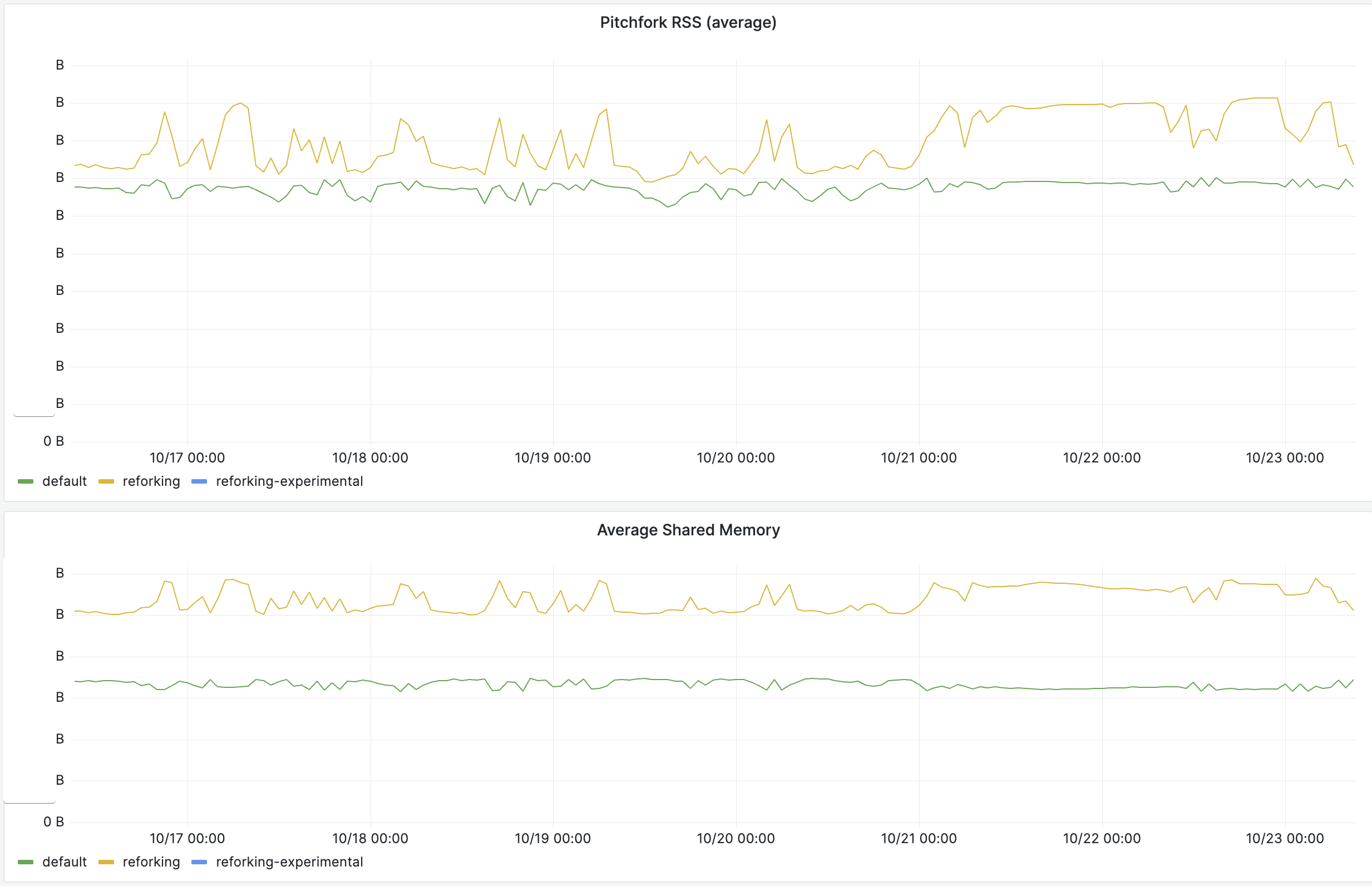
An amusing corollary is that reforked workers actually have a significantly higher RSS, but since a bigger part of it is shared, it translates to a significantly lower “real” memory usage:
0 based.