In September, 2020, our team at Shopify released a Ruby gem named Packwerk, a tool to enforce boundaries and modularize Rails applications. Since its release, Packwerk has taken on a life of its own, inspiring blog posts, conference talks, and even an entire gem ecosystem. Its popularity is an indication that Packwerk clearly filled a void in the Rails community.
Packwerk is a static analysis tool, similar to tools like Rubocop and Sorbet. Applied to a codebase, it analyzes constant references to help decouple code and organize it into well-defined packages.
But Packwerk is more than just a tool. Over the years, Packwerk’s approach to modularity has come to embody distinct and sometimes conflicting perspectives on code organization and its evolution. Packwerk’s feedback can change the entire trajectory of a codebase to a degree that distinguishes it from other tools of its kind.
This retrospective is our effort, as the team that developed Packwerk at Shopify, to shine a light on our learnings working with the tool, concerns about its use, and hopes for its future.
“I know who you are and because of that I know what you do.” This knowledge is a dependency that raises the cost of change. – Sandi Metz, Practical Object-Oriented Design in Ruby
Sandi Metz’ quote above captures the spirit from which Packwerk was born. The premise is simple. To use Packwerk, you must first do two things:
With this done, you can then run Packwerk’s command-line tool, which will tell you where constants from one package reference constants from another package in ways that violate your stated dependency graph. Violations can be temporarily “allowed” via todo files (package_todo.yml); this makes it possible to “declare bankruptcy” in a codebase by generating a todo file for existing violations and using Packwerk to prevent new ones from creeping in.
The pursuit of a well-defined dependency graph in this way should, in theory, make application code more modular and less coupled. If a section of an application needs to be moved, it can be done more easily if its dependencies are explicitly defined. Conversely, circular dependencies tangle up code and make it more difficult to understand and refactor.
In the metaphor of carrots and sticks, privacy is sugar. It’s easy to understand and has broad appeal, but it may not actually be good for you. – Philip Müller, original author of Packwerk (link)
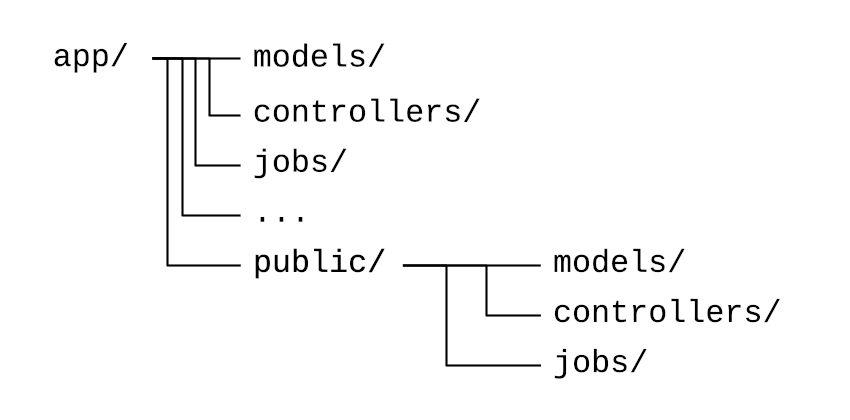
Packwerk acquired an entirely different usage in its early stages, in the form of “privacy checks” which could be enabled on the same set of packages above to statically declare public APIs. Constants that were placed in a separate public directory were treated as “public” and could be referenced from any other package. Other constants were considered “private” and references to them from other packages were treated as violations, regardless of dependency relationships.
As expressed in the quote above by Philip Müller, privacy checks were never intended to be the main feature of Packwerk, but it is easy to see their appeal. Dependencies in large sprawling codebases can be difficult to correctly define, and even harder to resolve. Declaring a constant public or private, in contrast, is simple, and closely resembles Ruby’s own concept of private and public methods.
Unfortunately, while easy to use, Packwerk’s privacy checks introduced several problems. Some of these were problems of implementation: the checks required a separate app/public directory for code that was meant to be public API. This broke Rails conventions on file layout by introducing a folder under app that denoted privacy level instead of architecture concepts. Confusion around where files should go resulted in new subdirectories being created for controllers and jobs, duplicating those that already existed under app. As public API, these subdirectories should have been documented and well thought-out, but Packwerk didn’t encourage this level of detail. Thus, we ended up with endless poorly-documented public code that was never meant to be public in the first place.
Yet there was a deeper problem, namely that privacy checks had transformed Packwerk into something it was never intended to be: an API design tool. Packwerk was being used to ensure that packages communicated via blessed entrypoints, whereas its original purpose was to define and enforce a dependency graph. Package A using package B’s code (even its public API) is not acceptable if package A doesn’t depend on B, yet we found developers were focusing on the design of their APIs over the dependencies in their code. This was drawing attention away from the problem the tool had been created to solve.
Given these issues, privacy checks were removed from Packwerk with the release of version 3.0.
We have found that the biggest issues with Packwerk are related to what the tool does not do for you: what it cannot see, what it cannot know, and what it does not tell you.
Using Packwerk starts with declaring your packages: what code goes where, and how each set of code depends on the rest. The choice of packages and their relationships can be fiendishly difficult to get right, particularly in a large codebase where historically everything has been global. While you can change your package definitions later, any such changes come with a potential cost in terms of the time and effort spent isolating code that now ends up back together. Packwerk provides no guidance here, and is happy with any choice you make. It will generate for you a set of todo files that get you to your stated goal. Whether this work will actually get you to a better place, however, is another question entirely.
Pushing the responsibility of drawing the dependency graph for an application onto the developer can often lead to incorrect assumptions on how code is coupled. This is particularly true if you only work with one section of a larger codebase, or don’t have a good grasp on dependency management and code architecture.
We have found that developers tend to group code into packages based strongly on semantic clues that in many cases have little relation to how the code actually runs. We have a model in our monolith, for example, that holds “shop billing settings”, including whether a shop is fraudulent. This model was placed in a “billing” package by virtue of its name, but this was the wrong place for it: detecting fraudulent shops is essential to handling any shop request, not just those related to billing details. Our solution was to ignore the semantics of its name and move it to the base of our dependency graph, making it available to any controller.
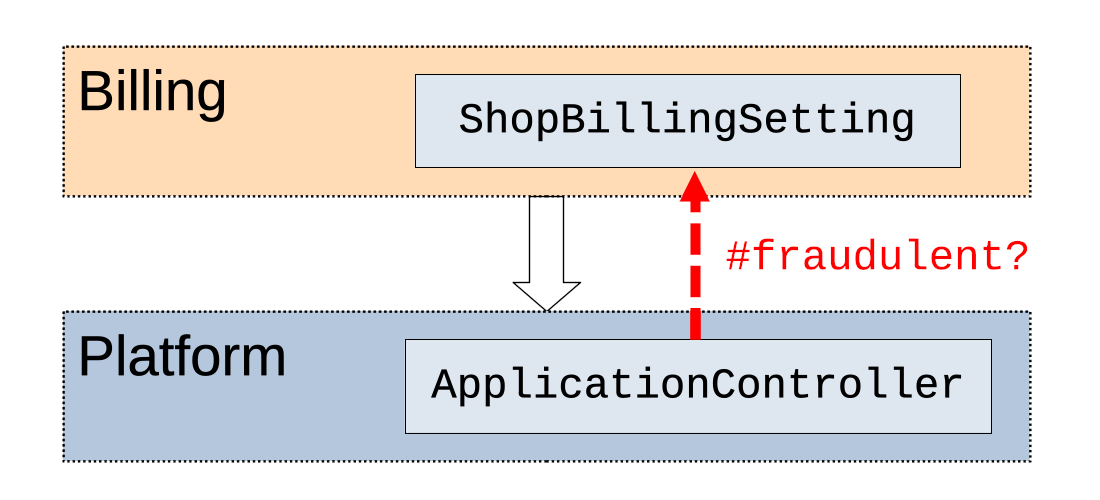
This kind of decision is hard because it goes against our intuition, as humans, to abide by the naming of things. Packwerk operates entirely on the basis of the high-level view of the codebase we provide it, which is often strongly influenced by this intuition; if the graph of dependencies it sees is misaligned with reality, then the effort developers exert resolving dependencies may bring little to no benefit. Indeed, such efforts may even make the code worse by introducing indirection, rendering it more complicated and harder to understand.
Even assuming a well-drawn dependency graph, the problem arises of how to resolve violations. Packwerk does not provide feedback on how to do this; it only sees constant references and how they relate to the set of packages you have provided. This makes it difficult to know if you’re doing the right thing or not when approaching fixes for dependency violations.
There are further blind spots that can make these problems worse. Like other static analysis tools, Packwerk is unable to infer constants generated dynamically at runtime. However, Packwerk has a far more limiting gap in its picture of application constants because of its dependence on Zeitwerk autoload directories. Constants loaded using mechanisms like require, autoload, or ActiveSupport::Autoload are untracked and invisible to the tool. As a result, a package that is well-defined according to Packwerk (has no violations left to resolve) may actually crash with name errors when its code is executed.
Further to Packwerk not seeing the full picture, if you’re using full Rails engines as packages like us, it doesn’t help with sorting through routes, fixtures, initializers, or anything outside of your app directory. Anything that isn’t referenceable with constants becomes implicit dependencies that Packwerk can’t see. This often causes more problems that are only visible at runtime.
The blind spots mentioned above become the most obvious when you actually attempt to run packaged code in isolation. Running in “isolation” here means loading a package together with its dependencies and nothing else. In theory, a package that has no violations, whose dependencies themselves also have no violations, should be usable without any other code loaded. This is the point of a dependency graph, after all.
Recently, we decided to put Packwerk to the test and actually create such a package. To keep things simple, we chose for this test the only part of our monolith that should, by definition, have no dependencies. This “junk drawer” of code utilities, named “Platform”, holds the low-level glue code that other packages use. Platform’s position at the base of the monolith’s dependency graph made it an obvious choice for our first isolation effort.
Platform, however, was not even remotely isolated when we started. Having a clean slate was important, so rather than begin with Platform itself, we instead carved out a new package under it that would only contain its most essential parts. Into this package, which we named “Platform Essentials”, we moved base classes like ApplicationController and ApplicationRecord, along with the infrastructure code that other parts of the monolith depended on to do pretty much anything. Platform Essentials would be to our monolith what Active Support is to Rails.
The exercise to isolate this package was an eye-opener for us. We achieved our goal of an isolated base package with zero violations and zero dependencies. The process was not easy, however, and we were forced to make many tradeoffs. We relied heavily on inversion of control, for example, to extract package references out of base layer code. These changes introduced indirection that, while resolving the violations, often made code harder to understand.
We were greeted at the zero violation goal line with a surprising discovery: a bug in Packwerk. Packwerk was not cleaning up stale package todos when all violations were resolved. The fact that this bug, which we patched, had been virtually unnoticed until then indicated that we were likely the first Packwerk user to completely work through an entire package todo file, years after its initial release. This confirmed our suspicion that the rate at which Packwerk was identifying problems to its users vastly outpaced their capacity to actually fix them (or interest in doing so).
Having resolved all Packwerk violations for our base package, we then attempted to actually run it by booting the monolith with only its code loaded. Unsurprisingly, given the issues mentioned in the last section, this did not work. Indeed, we had yet more violations to resolve in places we had never considered: initializers and environment files, for example. As mentioned earlier, we also had to contend with code that was loaded without Zeitwerk, which Packwerk did not track. We fixed these issues by moving initializers and other application setup into engines of the application, so that they were not loaded when we booted the base layer on its own.
With boot working, we went a step further and created a CI step to run tests for the package’s code in isolation. This surfaced yet more issues that neither Packwerk’s static analysis nor boot had encountered. With tests finally passing, we reached a reasonable confidence level that Platform Essentials was genuinely decoupled from the rest of the application.
Even for this relatively simple case of a package with no dependencies, our effort to reach full isolation had taken many months of hard work. On the one hand, this was far more than one might expect for a single package, hinting at the daunting scale of dependency issues left to address in our monolith. The fact that so much work remained to be done even after resolving dependency violations was an indication of Packwerk’s limitations and the additional tooling needed to fill gaps in its coverage.
In truth, though, the exercise was not really about Packwerk. It was about isolation, and whether such a thing was even possible in a codebase of this size, built on assumptions of global access to everything. And on this question, the exercise had been a resounding success. We did something that had never been done before in a timespan that had a concrete completion date. We implemented checks in CI to ensure our progress would never be reversed. We had made real, tangible progress, and Packwerk, given the right context, had played a key role in making that progress a reality.
Shopify organizes its monolith into code units called “components”. Components were created many years ago by sorting thousands of files into a couple dozen buckets, each representing its own domain of commerce. The monolith’s codebase was thus divided into directories with names like “Delivery”, “Online Store”, “Merchandising” and “Checkouts”. With such a large change, this was a great way at the time to partition work for teams, limit new component creation, and bring order to a codebase with millions of lines of code.
However, we quickly discovered that domains and the boundaries between them do not reflect the way Shopify’s code actually functions in practice. This was immediately obvious when running Packwerk on the codebase, which generated monstrously large todo files for every component. With every new feature added, these todo files grew larger. Developers could resolve some of these violations, but often the fixes felt unnatural and overly complicated, like they were going against the grain of what the code was actually trying to do.
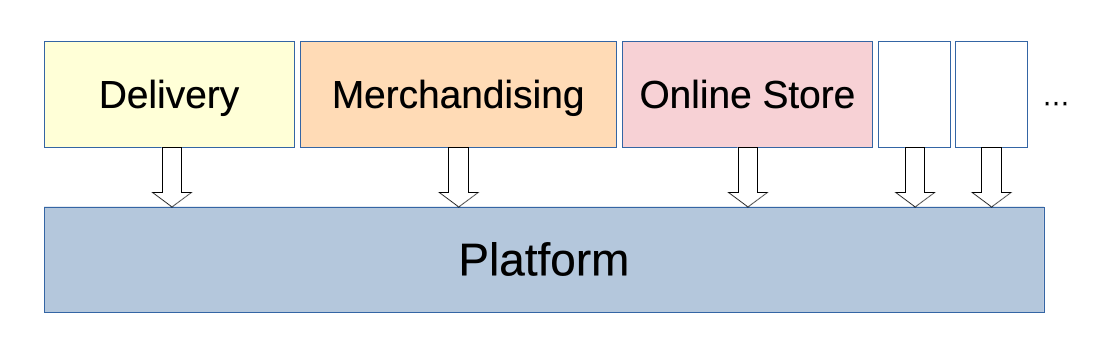
There was an important exception, however. The monolith’s Platform component, described earlier, was from the start a purely system-level concern. Along with a couple others like it, this component never fit into the mold of a “commerce domain”. This made it an oddball in a domain-centric view of the world. When we shifted our focus to actually running code, as opposed to simply sorting it, the purely functional nature of this component suddenly became very useful, however. Unlike every other component, Platform’s position in the dependency graph was obvious: it must sit at the base of everything, and it must have zero dependencies.
The focus on running code has instigated a rethink of how we organize our monolith. We are faced with a dichotomy: some components are domains, while others are designed around the functional role they play in the application. A checkout flow is a function defined as the code required for a customer to initiate a checkout and pay for their order. Our “checkouts” component, however, contains a number of concerns unrelated to this flow, such as controllers and backend code for merchants to modify their checkout settings. This code is part of the checkout domain, but not a part of checkout flow functionality.
Actually running packages in isolation requires them to be defined strictly on a functional basis, but most of our components are defined around domains. Recently, our solution to this has been to use components as top-level organizational tools for grouping one or more packages, rather than a singular code unit. This way, teams can still own domains, while individual packages act as the truly modular code units. This is a compromise that accommodates both the human need for understandable mental models and the runtime need for well-defined units of a dependency graph.
When attempting to modularize a large legacy codebase, it’s easy to get carried away with ideas of how code should behave. Packwerk lends itself to this tendency by allowing you, the developer, to define your desired end state, and have the tool lead you to that goal. You decide the set of packages, and you decide the dependency graph that links them together. Just work down the todo file, and you will reach the code organization you desire.
The problem with this view is that it is hard to know if it will lead to concrete results. Code exerts a powerful drive in the direction of function. It is much harder to bend this behavior to fit your mental models than it is to bend your mental models to fit what a codebase actually does.
We learned this lesson the hard way. We started with a utopian vision for our monolith, with modular code units representing domains of commerce and cleanly-defined dependencies relating them to each other. We built a tool to chart a course to our goal and applied it to our codebase. The work to be done was clear, and the path forward seemed obvious.
Then we actually sat down to do the work, and things began to look a lot less rosy. With hard-fought gains and messy tradeoffs, we made it through the todos for a single package, only to find that we were likely the first to reach the finish line. Our achievement turned out to be bittersweet, since our code was still broken and unusable in isolation. The utopia we had imagined simply did not exist, and the tool we thought would get us there was leading us astray.
What turned this situation around for us was the realization that running code, more than any metric, will always be the best indicator of real progress. Packwerk has its place, but it is just one tool of many to measure aspects of code quality. We achieved a small but significant victory by being highly pragmatic and broadening our understanding to leverage an approach we hadn’t originally considered.
Like many other tools in the Rails ecosystem, Packwerk is a sharp knife, and it must be wielded with care. Be intentional about how you use it, and how you fix the violations it raises. Always ask yourself if the violation is an error at the developer level, or at the dependency graph level. If it is at the graph level, consider adjusting your package layout to better match the dependencies of your code.
At Shopify, we often stress test our assumptions and revisit the decisions we made in the past. We have discussed removing Packwerk from our monolith, given the costs it incurs and the weaknesses and blind spots described earlier. For us, the technical debt introduced from privacy checking is still a long way from being paid off. Packwerk has however provided value in holding the line against new dependencies at the base layer of our application. However imperfect, its list of violations to resolve is an effective way to divvy up work toward a well-defined isolation goal.
Our learnings using Packwerk have informed a larger strategy for modularizing large Rails applications, one that is strongly oriented toward running code and executable results rather than philosophical ideals. While no longer as central as it once was, Packwerk still plays a role at Shopify, and will likely continue to do so over the years to come.