
How We Scaled Maintenance Tasks to Shopify's Core Monolith
In 2020, we built the maintenance_tasks gem as a solution for performing data migrations in Rails applications. Adopting the gem in Shopify’s core Rails monolith was not so simple, however! We had to adapt the gem to fit Core’s sharded architecture and to handle data migrations across millions of rows. Let’s take a look at how we did it.
A Refresher on Maintenance Tasks
In 2020, we built the maintenance_tasks gem as a solution for performing data migrations in Rails applications. It’s designed as a mountable Rails engine and offers a web UI for queuing and managing maintenance tasks.
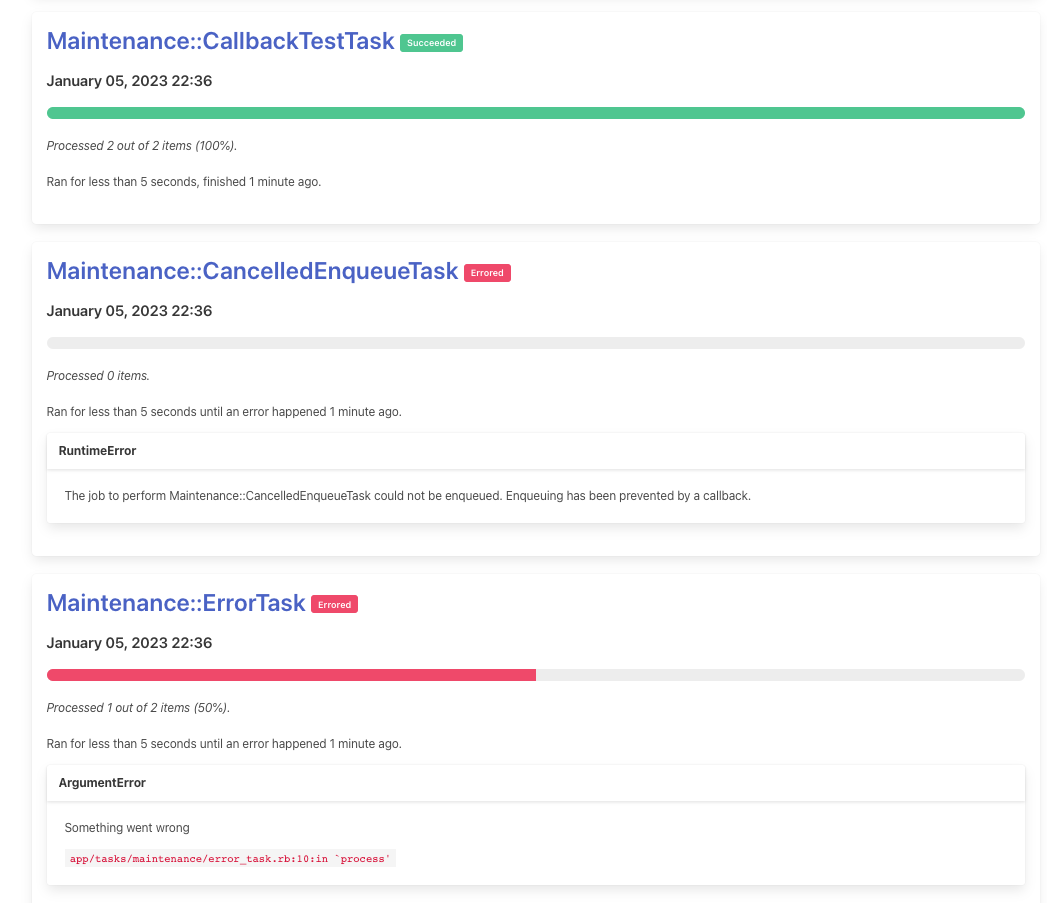
The Maintenance Tasks gem is designed as follows:
- A
maintenance_tasks_runstable is used to track information about a running task, including its name, the number of records that have been processed, the task’s status, etc. - The work to be done by a task is specified in a
Taskclass. The class must define two methods:#collectionand#process.-
#collectiondefines the collection of elements to be processed by the task. -
#processdefines the work to be done by a single iteration of the task on an element from the provided collection.
-
- A task can be kicked off from the UI, but also via a Ruby API using the
Runnerclass. - Running a task enqueues a
TaskJoband creates aRunrecord. The job iterates over the specified collection and performs the task’s logic. - The task job is responsible for updating progress on the
Runrecord.
For most Rails apps, installing maintenance_tasks is as simple as adding the gem and running the install generator
to create the proper database table and mount the engine in config/routes.rb. After successfully releasing v1.0
of the gem, we wanted to adopt it in Shopify’s Core monolith. We had a couple of challenges to overcome:
- Shopify Core’s background job infrastructure is sophisticated. It needs to handle shops being moved across shards during failovers, complex throttling behaviour, logging to Kafka and other observability services, among other things. We needed to ensure the gem integrated seamlessly with the existing job infrastructure.
- Shopify Core is sharded. Consequently, the gem wouldn’t work out of the box. We needed to extend the maintenance tasks infrastructure to leverage the gem in a sharded context, and to coordinate tasks across shards.
Integrating Maintenance Tasks with the Existing Job Infrastructure
Our general recommendation for customizing
the job class to be used by gem is to set MaintenanceTasks.job in an initializer, with the specified job inheriting from MaintenanceTasks::TaskJob. In Shopify Core, the bulk of our background job logic is found in a base
ApplicationJob class. We wanted to leverage that job class, so we ended up extracting the bulk of the job logic
in the gem to a module, MaintenanceTasks::TaskJobConcern. We still recommend that Rails apps requiring custom jobs inherit from MaintenanceTasks::Job, an empty class that includes TaskJobConcern, but in our monolith we specified a custom
job class that inherits from ApplicationJob and includes the task job logic via MaintenanceTasks::TaskJobConcern.
Making the Maintenance Tasks Gem Work with Core’s Architecture
The main challenge to tackle in adopting the Maintenance Tasks gem in Shopify Core was getting it to work with the podded architecture of the application. The distinction between the terms “shard” and “pod” are subtle, so let’s clarify the language a bit here:
- A shard is a database shard, or a horizontal partition of data. Shops 1-1000 might be stored on shard 0, shops 1001-2000 on shard 1, and so on. Sharded data is always scoped to a particular shop.
- A pod is considered to be an independent Shopify, and includes not only a database shard, but also other infrastructure concerns such as Redis, Memcached, etc. A pod is a superset of a shard.
When we talk about Shopify Core being podded, we’re saying that there are many pods running independent versions of Shopify. Each pod has not only its own database, but also has its own job workers and infrastructure. To run a backfill task against all shops at Shopify, we’d need to kick off a task job on each pod so that rows across each shard would be updated.
Shopify Core also employs a concept called “shard m” or the main pod context. In addition to shop-scoped database shards, we have an “m-shard” database that stores data shared across shops: api permissions, domains, etc.
We determined that the requirements for adopting the gem in Core were as follows:
- Tasks would need to be run across pods (one or more), or in the main pod context.
- When running a task across multiple pods, the Maintenance Tasks UI should aggregate the task’s progress across all pods, in addition to surfacing information about the task at the level of each pod.
- Stopping a task would mean stopping the task job on each pod.
We decided to expand on the gem’s architecture:
- Each shard would have its own
maintenance_tasks_runstable that would track a running task on a given pod. - We’d introduce a
maintenance_tasks_cross_pod_runstable in the m-shard database that would aggregate task run data across all pods for a given task.
We still had a big problem, though: there is a strict boundary between the pod context and the main pod context. Podded jobs cannot be enqueued from the main pod context, because this would mean enqueueing jobs across data centres. We needed a way to queue task jobs across multiple pods, and also a way to have the podded tasks report their progress back to the main pod context in order to aggregate task data across pods. Luckily for us, we were able to leverage tooling that already existed in Shopify’s monolith: the cross pod task framework.
Shopify Core’s Cross Pod Task Framework
Shopify Core’s CPT framework is a system that can be used to handle queuing and synchronizing work across pods. Here’s a simplified view of how it works:
- A synchronization job is queued in the main pod context, with an argument specifying which pods should be targeted.
- This job creates a
CrossPodWorkUnitrecord for each pod that should be targeted. These records are all stored in the main pod context in across_pod_work_unitstable. - There is a scheduled processing job that runs every minute on each pod, and looks for work units that are queued on the current pod.
- We call
#runon every queued work unit. This method performs some logic and then marks the unit as either processing (meaning that there is more work to be done), or finished. - A synchronization job is scheduled to run every minute in the main pod context, and handles synchronizing data
across the work units. It offers certain hook methods that
CrossPodWorkUnitsubclasses can leverage.
To extend Maintenance Tasks to Core, we wrote two new work unit classes: MaintenanceTaskStart handles queueing new
tasks across pods and syncing progress from the pods back to CrossPodRun in the main pod context, and
MaintenanceTaskStop handles pausing or cancelling a task across pods.
Here’s an overview of how the MaintenanceTaskStart cross pod work unit operates with the maintenance_tasks gem
(you might need to zoom in!):
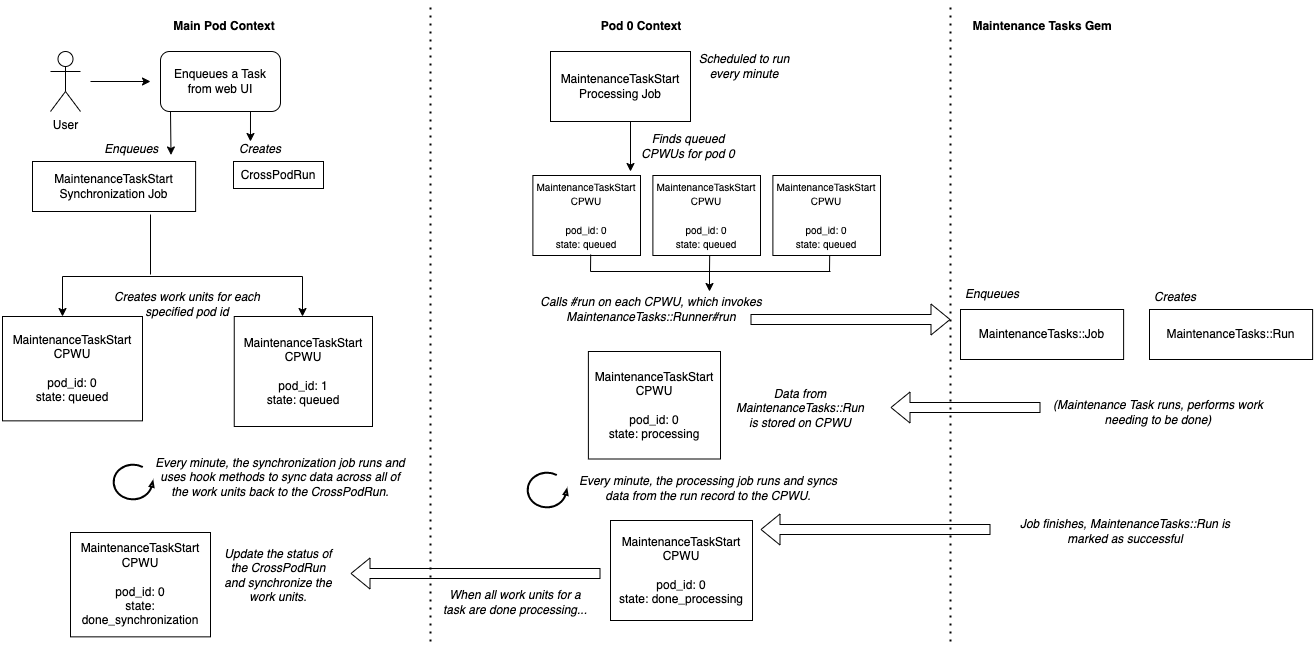
The process looks something like this:
In the main pod context
- A user enqueues a maintenance task from a Web UI. This request takes place in the main pod context.
- A
MaintenanceTaskStartsynchronization job is enqueued, and aCrossPodRunrecord is created to track the task’s progress, aggregated across all pods (in this case, we have two pods: 0 and 1). - The synchronization job creates a
MaintenanceTaskStartcross pod work unit (CPWU) for each pod.
On pod 0 (and similarly, pod 1)
- Every minute, a
MaintenanceTaskStartprocessing job runs and searches forMaintenanceTaskStartCPWUs that are queued for pod 0. - The processing job will call
MaintenanceTaskStart#runon each of these work units. Recall that#runis where the bulk of the work unit’s logic should live. -
MaintenanceTaskStart#runinvokesMaintenanceTasks::Runner#run, which is the gem’s Ruby entrypoint for running a maintenance task. The gem handles everything as it would with a regular, unsharded Rails application, as described in A Refresher On Maintenance Tasks. - As soon as the runner is invoked, details about the
MaintenanceTasks::Runrecord the gem created are stored in the cross pod work unit’s attributes. - After this, the cross pod work unit is moved to a state of processing.
- The processing job that runs every minute also looks for units that are processing on pod 0, and calls the
#runmethod on them. If the runner has already been invoked for that work unit,#runwill synchronize the updated details from theMaintenanceTasks::Runrecord to the work unit.
In the main pod context
- Back in the main pod context, a
MaintenanceTaskStartsynchronization job is also kicked off every minute. Its responsibility is to look at all of theMaintenanceTaskStartwork units for a given task, and invoke some behaviour depending on the state of those work units. If all of the work units for a maintenance task are processing, the synchronization job will invoke a processing method, which aggregates information across all of the work units and persists it to theCrossPodRun. For example, the sync job might sum the number of records processed by the task on each pod, and persist it to theCrossPodRunas the “total number of ticks performed”.
On pod 0
- At some point, the gem finishes running the maintenance task, and the podded run is marked as successful.
- This information propagates to the
MaintenanceTaskStartwork unit as soon as a processing job runs. - Once the
MaintenanceTaskStartwork unit identifies that the maintenance task has finished, it marks the work unit as done_processing.
In the main pod context
- Once all of the work units for a task are done_processing, the synchronization job invokes the “after done
processing” function on all of the work units. This involves updating the status of the
CrossPodRun, setting theended_attime, etc. - After this, the synchronization job considers all of the units to be synchronized, and moves them from done_processing to done_synchronization.
Just as with the MaintenanceTaskStart work unit, if a user cancels a task from the web UI, we enqueue a synchronization job that
creates MaintenanceTaskStop work units for each pod. These work units send a #cancel message to the active
MaintenanceTasks::Run for the current pod, which results in the maintenance task stopping (this is all handled by the
gem itself). Note that the MaintenanceTaskStop work unit is only responsible for sending the #cancel message to the
podded run; it is still the MaintenanceTaskStart work unit that will sync information back to the CrossPodRun once
the podded run has been marked as cancelled and the task job has stopped.
Conclusion
As you can see, integrating the Maintenance Tasks gem with Shopify’s Core monolith required some careful thinking.
While we could rely on the gem to do most of the heavy lifting related to running a maintenance task, we had to extend
the system to work in a sharded context and to integrate with the existing background job infrastructure. The concept
of a CrossPodRun was introduced to offer users a snapshot of what was happening with their task, without requiring
them to examine the details of every pod.
The work to adopt maintenance_tasks in Core is broader than what was discussed in this blog (the actual web UI had to
be developed from scratch to factor in sharding!), but the biggest challenge to solve was executing tasks across pods.
Hopefully at this point you have a general idea about how we approached scaling the maintenance_tasks gem to our massive,
sharded Rails monolith.