
How to load code efficiently in Ruby
In Ruby, we usually don’t think about memory. In frameworks like Ruby on Rails, we don’t even have to write statements to load our code. While Ruby has tools that abstract these concepts away from us, it is useful to understand how our apps get loaded into memory.
Since the dawn of Ruby, there was require: a simple method that takes a string path argument and loads the file it finds. Simple, effective, and a cornerstone of the language to this day. require has a sibling method called require_relative, which is the preferred way to require a file with a path relative to the current file.
One level above require is autoload. autoload takes a symbol representing a constant and a string path to load it from. This method is clever because it waits to load the file you give it until the constant you specify is referenced, which avoids loading code you aren’t using. Under the hood, autoload uses require to load the code lazily. Active Support has an abstraction on top of autoload, which adds some conveniences to the standard ruby method.
The third, less used method for code loading is load. Similar to require, it loads code from a file, but has some subtle differences. load will always attempt to load a file, while require only loads a given file once (methods like this are called “idempotent”). As of Ruby 3.2, it also supports loading code into a specified module, which can be helpful in niche code isolation use-cases.
Visualizing memory consumption
So, now that we understand the three main institutions of how code is loaded in Ruby, how do we use them efficiently? Well, the short answer is not to. The fastest program you can possibly write is an empty file and the most efficient code can be written without any keystrokes. While you may have a hard time selling this viewpoint to your manager, we can keep it in mind when optimizing existing code.
A program expands into memory much like a balloon expands with air. Typically, loading a file triggers a chain reaction of other files to load. These files may be required immediately, or autoloaded lazily. Either way, a program’s memory usage often starts low and expands over time. Though, there should be an upper-bound to how much memory a program uses, otherwise there may be a memory leak.
As a program grows in complexity, it also grows in lines of code. More lines of code to load leads to more space in memory. In essence, this means the more you write, the slower the program will usually be. Ruby has several language-level mechanisms to help speed up your code, but you shouldn’t trust them to do all the optimizing for you.
The most notable feature in any language to help developers manage memory is Garbage Collection (GC). GC runs at regular intervals in Ruby to determine which objects are reachable and unreachable. If any objects can’t be used (they existed in a method that has finished executing, for example), they are cleaned up. While this is incredibly useful, it doesn’t solve memory management for apps, especially as they grow in size and complexity.
Suffice to say, a program should only load what it needs to, when it needs to. This is especially true when loading any dependencies. A “less is more” ideology helps keep things lean and fast, and applies to more than just memory management. Style guides, type checkers, benchmarks, and profilers can all help shape code into the best, most efficient version of itself.
To illustrate this, we can observe the difference between require and autoload in profiles of a 2000 file ruby library. The first graph shows the library loading using require, and the second shows the same library loaded with autoload. You’ll notice that the autoload version runs significantly faster (176ms vs <1ms) due to the fact that it registers the files to load later, rather than loading the code immediately with require.
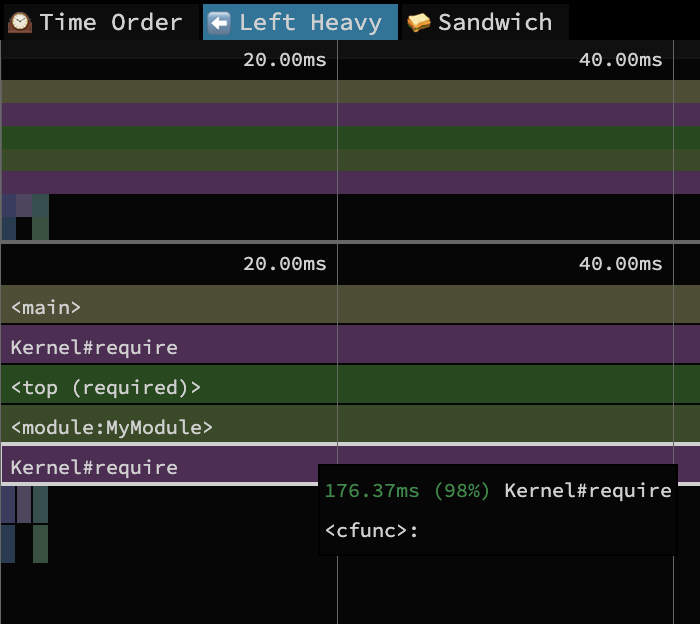
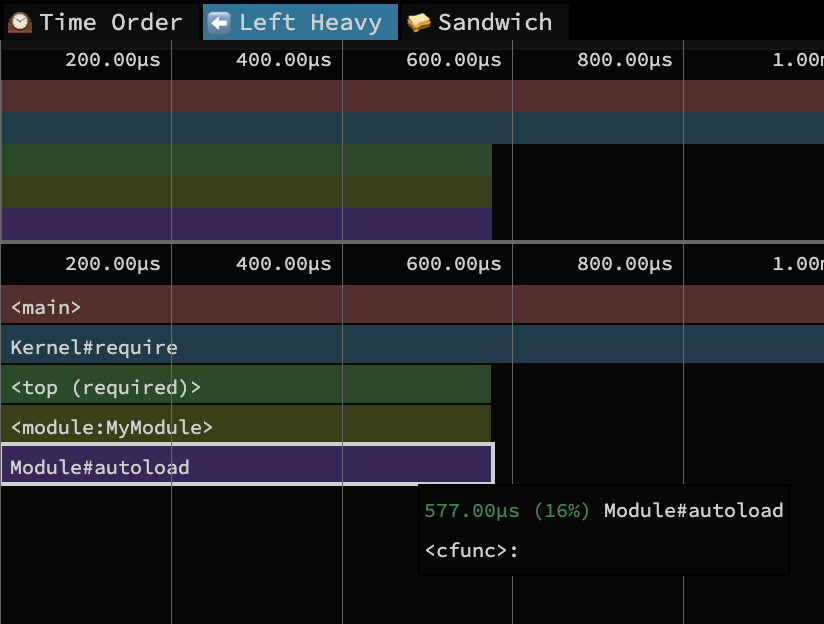
Loading code responsibly
Logically, if autoload is faster than require, you may ask “why not just autoload everything?”. If we only want to load what a program uses, why bother using require at all? The answer is that making programs lazy incurs a cost. Autoloading usually greatly improves the developer experience, but the user experience suffers as a result. Looking at a web framework like Ruby on Rails, we can understand why.
Rails uses autoloading in development and test modes. This way, apps can boot minimally and wait until the first request to load most of the application. This allows developers to boot the app quickly for testing, profiling, and benchmarking. Most of the time, a development mode server will be booted for a very specific purpose and then discarded.
Conversely, in production, autoloading is clearly a problem for users. Our expectations in this environment are the exact opposite of what we want in development. We want the app to do as much work as possible while booting, in order to optimize for server response time and process forking.
Rails is often a Rubyist’s first encounter with the concept of autoloading, and it can be a little confusing. Rails apps are able to load both lazily and immediately with a concept called “eager loading”. Eager loading takes autoloaded code and evaluates it early, and all at once. Thus, development and test mode are autoloaded, whereas production mode is eager loaded to get the best of both worlds.
Picking the right tool for the job
At this point, you may be wondering how Rails autoloads code without having to write autoload statements. This is done with a gem called Zeitwerk. It is a convention-based tool that looks at ruby files in a directory and sets up autoloads for them. Zeitwerk isn’t exclusive to Rails, and is used by many other gems as a standalone solution to manage code loading (similar to ActiveSupport::Autoload, which is an entirely separate solution).
With require, autoload, and Zeitwerk available to use, which makes sense for your Ruby application? Well, if you have the freedom to choose, it often comes down to scale. When building a new project (and you’re not using a framework like Rails that opts you into autoloading automatically), you should always start with require, and consider transitioning to autoload or Zeitwerk later based on your app’s needs.
It is important to realize that autoloading is just a mechanism for convenience for you and your computer. Autoloading might not be needed if your program expects a constant to be present at all times (or depends on a feature like Class#descendants). Zeitwerk may not be worth it unless your program is big enough to justify the additional complexity. Like in Rails, it is also possible to mix loading mechanisms where needed.
Moving from one loading mechanism to another
This is a good time to talk about upgrade paths for code loading mechanisms. When you choose to start autoloading, how do you introduce it to your codebase? The best way to start is by structuring your application’s constants into logical branches. Nesting related code under specific constants is crucial to making autoload work.
For example, imagine you have a command line application called MyApp, and this application has 2 different commands. You could organize the two commands into two different groups of code and nest them under separate constants (eg. MyApp::CommandA and MyApp::CommandB). These constants could then be autoloaded as long as they are defined in individual files, which would effectively only load the command the application is using.
# lib/my_app.rb
module MyApp
autoload(:CommandA, "my_app/command_a")
autoload(:CommandB, "my_app/command_b")
end
MyApp::CommandA # loads lib/my_app/command_a.rb
In the wild, a more concrete example of this is the Octokit gem. There is ongoing work to make the library use autoload rather than require. Once completed, applications will load the gem code section-by-section like the example above, saving a substantial amount of load time as a result (roughly a 2x improvement).
How about going from using autoload statements to Zeitwerk? The first step in this process would be to make sure your file names and class names match. Similar to autoloading in Rails, you need to have file names that match the constants they define. After that, you can remove any old autoload statements and setup Zeitwerk to manage your autoloads for you.
Using the same CLI application example, commands need to be defined in separate files with specific file names. MyApp::CommandA would be defined in lib/my_app/command_a.rb and MyApp::CommandB would be defined in lib/my_app/command_b.rb. With the right file structure, all the developer needs to do to use Zeitwerk is set up a loader object in the main file entrypoint.
# lib/my_app.rb
require "zeitwerk"
module MyApp
class << self
def loader
@loader ||= Zeitwerk::Loader.for_gem
end
end
end
MyApp.loader.setup
MyApp::CommandA # loads lib/my_app/command_a.rb
We can see a real-world example of this in the dry-rb gem. Zeitwerk was a good solution for the dry suite of gems because of the scale and file count of the project. They were using plain old require, but leveraging Zeitwerk cut down load time in test suites and downstream applications significantly.
It would seem there is a time and a place for all of Ruby’s different instruments for loading code. The one you choose may be dictated by your choice of framework, the size of your project, or a scaling decision in the future. No matter what you choose, make sure you’re only loading what you need, when you need it, and leveraging tools within the Ruby ecosystem to see how large your applications really are.