
Rewriting the Ruby parser
At Shopify, we have spent the last year writing a new Ruby parser, which we’ve called YARP (Yet Another Ruby Parser). As of the date of this post, YARP can parse a semantically equivalent syntax tree to Ruby 3.3 on every Ruby file in Shopify’s main codebase, GitHub’s main codebase, CRuby, and the 100 most popular gems downloaded from rubygems.org. We recently got approval to merge this work into CRuby, and are very excited to share our work with the community. This post will take you through the motivations behind this work, the way it was developed, and the path forward.
If you’re unfamiliar with the concept of parsers or how they apply to Ruby, there’s a background section available at the bottom of this post that should get you up to speed.
Motivations
The current CRuby parser has a couple of long-standing issues that we wanted to address. Broadly these fall into four categories: maintainability, error tolerance, portability, and performance. We’ll go into each of these in turn below.
Maintainability
Maintainability is almost entirely subjective, or at least is very difficult to measure. The overall concept can be broken down into many different facets, including but not limited to how easy it is to: read and understand the code, contribute to the code, change the code, document the code, and test the code.
The current CRuby parser has no real documentation that we could find. There have been external projects that have attempted to document its design, notably the Ruby Hacking Guide from 2002 and Ruby Under A Microscope from 2013. Other than those decades-old efforts, the best chance you have is reading the 14 thousand-line parse.y file and trying to understand it. This is a daunting task to say the least, and one that we don’t think anyone should have to do.
Due to its complexity, the parser is also difficult to change. Consider bug #19392 from two months ago, when it was discovered that def test = puts("foo") and puts("bar") doesn’t work at all like you would expect. Because of the way the parser is structured, it’s not possible to fix this bug without breaking other code. This is a common theme in generated parsers, where seemingly simple changes can have far-reaching consequences.
Looking at the contribution list, it’s unsurprising to find that the existing parser can only be maintained by a couple of people. In the 25 years that the parser has existed, only 65 people have contributed to it, and only 13 of those have contributed more than 10 commits. In the last year, only 9 people have contributed to the parser, of which only 2 have contributed more than 10 commits.
Maintainability is at the heart of open-source, and unfortunately the situation we find ourselves in is devoid of a maintainable parser.
Error tolerance
Error tolerance is the ability of a parser to continue parsing a program even if it encounters syntax errors. In other words, an error-tolerant parser can still generate a syntax tree even in the presence of syntax errors.
Error tolerance is important for a number of reasons. Editors, language servers, and type checkers like Sorbet or steep, rely on parsers to provide accurate metadata — types, arguments, scope, etc. — about the code being edited or analyzed. Without an error-tolerant parser, that metadata can get dumped at the first syntax error. This pushes the error-tolerance problem down to the consumers of the parser who have to try to reconcile their lack of metadata to get back to a stable state, which can be difficult and error-prone.
As of Ruby 3.2, the CRuby parser has some minor error tolerance, but nothing that you would call a systemic approach. This means even the most trivial syntax errors result in the parser failing to generate a syntax tree. The downstream effects of this are that when you have multiple syntax errors in your file (usually because of copy-pasting) you end up having to fix them one at a time, which is a very slow process. These slower cycles can be frustrating, and stand in contrast to the ideals of “developer happiness” that Ruby is known for.
As an example, consider if your editor could only display one error at a time. Each time one is fixed, the next would appear. This can be time-consuming and frustrating for developers. Consider the following snippet:
class Foo
def initialize(a: 1, b = 2)
true &&
end
There are 3 syntax errors in the source above (the order of parameters, the missing expression on the right side of the &&, and the missing end keyword). Running this through ruby -c today (which checks for syntax errors) you get:
test.rb: test.rb:2: syntax error, unexpected local variable or method (SyntaxError)
def initialize(a: 1, b = 2)
^
test.rb:4: syntax error, unexpected `end'
end
^~~
This mentions the first issue, the second issue is confused for something else, and the third is missing entirely.
Error tolerance is therefore something we wanted to bake into YARP from the beginning, accounting for it at every level of the design.
Portability
Portability refers to the ability to use the parser outside of the CRuby codebase. Currently, the parser is tightly tied to CRuby internals, requiring data structures and functions only available in the CRuby codebase. This makes it impossible to use in other tooling.
Accordingly, the community fractured and developed multiple solutions, each with their own issues. Over the years there have been many other parsers written, almost all by taking the grammar file and generating a new kind of parser. In our research, we found parsers written in 9 different languages. Some of these made their way into academic papers, otherwise into production systems. As of writing, we know of 12 that are being actively maintained (6 runtimes, 6 tools):
- CRuby
- mruby
- JRuby
- TruffleRuby
- ruruby
- natalie
- Ripper
- parser
- ruby_parser
- tree-sitter-ruby
- Sorbet
- lib-ruby-parser
Each of these parsers besides the reference implementation have their own issues. This means that each of the tools built on these parsers therefore inherit those same issues. The fracture therefore spreads into tooling. For example, some tools are based on Ripper, including Syntax Tree, rubyfmt, rufo, syntax_suggest, and ruby-lsp. Even more are based on the parser gem, including rubocop, standard, unparser, ruby-next, solargraph, and steep. Even more are based on the ruby_parser gem, such as debride, flay, flog, and fasterer.
Clearly this is far from optimal. Every time new syntax is introduced into Ruby, all of the parsers have to update. This means opportunities to introduce bugs, which all get flushed down to their corresponding tools. As an example, Ruby 2.7 was released 4 years ago, and it came along with pattern matching syntax. Of the 10 non-CRuby parsers, only 5 of them support all of pattern matching to this day, and only 2 of them without any caveats.
To keep up to date with the CRuby parser, every one of these parsers must carefully watch for any changes to parse.y and attempt to replicate them in their own language/runtime. This is a massive amount of work for a significant number of people who could instead all be helping maintain and improve a single parser instead.
Portability also has to do with the usability of your syntax tree. Even if you can extract the syntax tree from the parser, if your syntax tree is too tightly tied to your runtime, it’s not portable. We’ll revisit this topic later when we discuss the design of YARP’s tree.
Performance
Over the years, processors and C compilers have gotten much better using a couple of techniques. These include pipelining, inlining functions, and branch prediction. Unfortunately, the parsers generated by most parser generators make it difficult for any of these techniques to apply. Most generated parsers operate with a combination of jump tables and gotos, rendering some of the more advanced optimization techniques impotent. Because of this, generated parsers have a maximum performance cliff that is extremely difficult to overcome without significant effort.
Development
With those problems and motivations in mind, last May we sat down and started designing solutions. It became clear pretty quickly that while a full-scale rewrite was a daunting task, it would be necessary to address all of the issues we had identified. So, we sat down to design what would become Yet Another Ruby Parser.
Design
Initially we created a design document for the project, which you can still find. We shared this document internally before also going to discuss with Matz and the CRuby team, as well as JRuby, TruffleRuby, and maintainers of as many tooling gems as we could find (notably including parser and irb).
Some of the more important design decisions that came out of these discussions are included below. Once Matz and the CRuby team were happy with the design, agreed on the approach, and determined that they would merge YARP in when it was ready, the work began in earnest.
Language
The parser would be written in C. While there was some lively debate about the implementation language, we ended up settling on C. Other options that were considered included C++ and Rust with various interop options (even WASM cross-compilation). There ended up being two compelling reasons that settled the decision. The first is technical: the parser should be able to target any platform that has a C compiler. The second is human: the Ruby parser is going to be maintained by the CRuby team which is a group of C developers. Since one of our main stated goals is maintainability and these are the people that will be maintaining it, it made sense to use the language they were most comfortable with.
Structure
The parser would be a hand-written recursive descent parser. This follows the trend of most major programming languages. Of the top 10 languages used by developers, 7/10 of them are hand-written recursive descent. Many tools have undergone the same switch from Bison to hand-written, for example gcc and golang. You can also find reasons why C# decided to go with this approach.
The three exceptions of the languages that don’t use hand-written recursive descent are Python, PHP, and Ruby. PHP and Ruby currently use Bison, whereas Python also recently switched to another flavor of recursive descent called PEG parsing. For more on that, see PEP-617. That article is particularly interesting in that it outlines some of the ambiguities in the grammar that you have to work around in the same way we had to historically work around them in Ruby. As an example they cite that in the below snippet:
with (
open("a_really_long_foo") as foo,
open("a_really_long_baz") as baz,
open("a_really_long_bar") as bar
):
it’s actually impossible to express this grammar for context managers using LL(1) parsing (the style of parser they were generating) because the open parenthesis character is ambiguous in this context. To get around it they made their grammar more ambiguous and then enforced that the actual grammar was enforced in their tree builder.
It’s not entirely surprising that more established languages would move away from Bison. Bison is a tool meant to generate parsers for context-free grammars. These are classes of languages where each rule in the grammar can be reduced to a deterministic set of tokens. Ruby’s grammar — as we saw with Python’s — requires quite a bit of context to parse correctly, making it fall into the set of grammars labeled context-sensitive. To get Bison to generate a parser that can be used by CRuby, a lot of the context, logic, and state has been pushed into the lexer. This means you cannot accurately lex Ruby code without keeping the whole set of parsing state around.
Laurence Tratt, a professor at King’s College London has done extensive research into this area. His work was actually cited three times at Ruby Kaigi this year, in The future vision of Ruby Parser, Parsing RBS, and our own talk on YARP. In the first talk in which his work was cited, in the second paragraph he writes:
It is possible to hand-craft error recovery algorithms for a specific language. These generally allow better recovery from errors, but are challenging to create.
Then, in a blog post specifically about LR versus recursive descent parsing, he states:
Existing languages have often evolved in a manner that makes it difficult, or impossible, to specify an LR grammar. There’s no point in trying to fight this: just use recursive descent parsing.
and
If you need the best possible performance or error recovery, recursive descent parsing is the best choice.
The reality is, Ruby’s grammar cannot be accurately parsed with an LR parser (the kind of parser that Bison generates) without significant state being stored in the lexer. Most of the programming community has come to the same conclusion about their own parsers and have therefore moved toward hand-written recursive descent parsers. It’s time for Ruby to do the same.
The last reason to switch to hand-written recursive descent actually comes from Matz himself. In version 0.95 of Ruby — released in 1995 — a small ToDo file was included in the repository. One of very few items in that file was:
Hand written parser(recursive decent)
API/AST
Initially, we had intended on keeping the same syntax tree as CRuby, to cause the least amount of disruption. However, after discussion with the various teams of both runtimes and tools, it was decided to design our own tree from the ground up. This tree would be designed to be easy to work with for both runtimes and tools. It would also be designed to be easy to maintain and extend going forward.
The current tree in CRuby sometimes contains information that is irrelevant to consumers and sometimes is missing critical information. As an example, the concept of a vcall is a parser concern: it is an identifier that could be a local variable or a method call. However, this is resolved at parse time. It is still exposed in the Ripper API though, leading to confusion as to its meaning. Contrastingly, the tree is almost entirely missing column information, which is critical for usage in linters and editors.
Along with the tree redesign, we worked closely with the JRuby and TruffleRuby teams to develop a serialization API that would allow for these runtimes to make a single FFI call and get back a serialized syntax tree. Once they have the serialized syntax tree, through our structured documentation they can generate Java classes to deserialize it into objects that they can use to build their own trees and intermediate representations.
The tree redesign has ended up being one of the most important parts of the project. It has delivered something that Ruby has never had before: a standardized syntax tree. With a standard in place, the community can start to build a collective knowledge and language around how we discuss Ruby structure, and we can start to build tooling that can be used across all Ruby implementations. Going forward this can mean more cross-collaboration between tools (like Rubocop and Syntax Tree), maintainers, and contributors.
Building
With the design in place, we went about implementing it. During implementation, it quickly became clear that the biggest hurdle was going to be a sufficiently extensive test suite. Since we had our own tree, it meant we couldn’t test against any existing test suites. Fortunately, we implemented parity with the lexer output, so we could test to ensure the tokens that our parser produced matched the existing lexer. Using this approach, we incrementally made progress toward 100% parity in lexer output against the Shopify monolith. Once we hit that, we worked on ruby/ruby, rails/rails, and various other large codebases. Finally, we pulled down the top 100 most downloaded gems from rubygems.org.
Along the way, we encountered all kinds of challenges, particularly related to the ambiguities in the grammar. If you’re interested, they are a fun detour through some of the eccentricities of Ruby, detailed at the bottom of this post in the challenges section.
Maintainability
From the start we wanted to be focused on the problems we initially noted. The make this parser as maintainable as possible, every node in the tree is documented with examples and explicitly tested. You can find that documentation here. You can also find documentation for as much of the design as we could fit into markdown in here. Finally, there is copious inline comments to make it as maintainable as possible.
Fortunately since open-sourcing the repository at the beginning of this year, we’ve had 31 contributors add code to the parser. We’ve been working to improve our contributing guidelines and guidance to make it even easier to contribute going forward.
Error tolerance
YARP includes a number of error tolerance features out of the box, and we are planning on adding many more in the months/years to come.
Whenever source code is being edited, it almost always contains syntax errors until the developers gets to the end of the expression. As such, it’s common for the underlying syntax tree to be missing tokens and nodes that it would otherwise have in a valid program. The first error tolerance feature that we built, therefore, is the ability to insert missing tokens. For example, if the parser encounters a missing end keyword where one was expected, it will automatically insert the missing token and continue parsing the program.
YARP can also insert missing nodes in the syntax tree. For example, if the parser encounters an expression like 1 + without a right-hand side, it will insert a missing node for the right-hand side and continue parsing the program.
Additionally, when YARP encounters a token in a context that it simply cannot understand, it skips past that token and attempts to continue parsing. This is useful when something gets copy-pasted and there is extra surrounding content that accidentally sneaks in.
Finally, YARP includes a technique we’re calling context-based recovery, which allows it to recover from syntax errors by analyzing the context in which the error occurred. This is similar to a method employed by Microsoft when they wrote their own PHP parser. For example, if the parser encounters:
foo.bar(baz, qux1 + qux2 + qux3 +)
it will insert a missing node into the + call on qux3, then bubble all of the way up to parsing the arguments because it knows that the ) character closes the argument list. At this point it will continue parsing as if there were nothing wrong with the arguments.
Putting this all together, if we take our snippet from above again, you can see the red underlines that YARP will add through its language server to indicate the location of every error in the file:
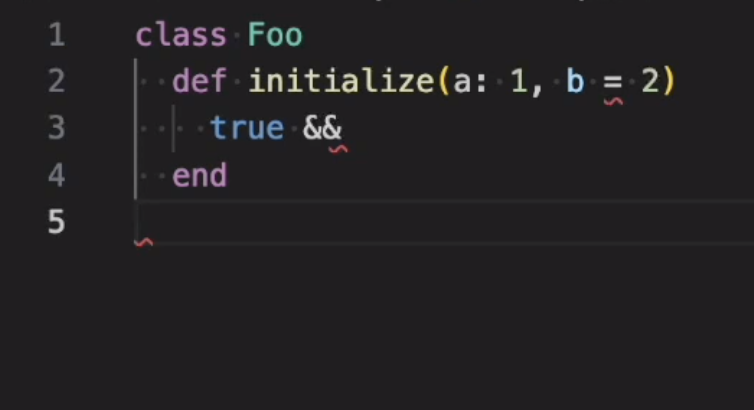
Going forward, there are many more techniques we’d like to explore related to error tolerance, but we’re happy with the state of the parser as it is today. If you’d like to see it in action, YARP ships with a language server and VSCode plugin that you can use to try it out. You’ll notice in the document describing how it works, that multiple syntax errors can be displayed in the editor at once, because of the existing error tolerance features.
Portability
YARP has no dependencies on external packages, functions, or structures. In other words it is entirely self-contained. It can be built on its own and used in any tooling that needs it. In languages with good FFI or bindgen support, this can mean directly accessing the parse function and its returned structures directly. Going forward, this means you could build Ruby tooling in languages like Rust or Zig with minimal effort.
For languages without this support or for whom calling C functions can be expensive, we provide a separate serialization API. This API first parses the syntax tree into its internal structure, then serializes it to a binary format that can be read by the calling language/tool. This API was designed specifically with JRuby and TruffleRuby in mind, and members of those teams have been actively helping in its development.
At this point JRuby has a functional prototype and TruffleRuby has merged YARP in and is actively working on making YARP its main parser. One interesting finding from this process was that YARP deserialization is around 10 times faster than parsing. Going forward, it’s possible that TruffleRuby could to ship serialized versions of the standard library for faster boot speeds.
With both the C and serialization APIs in place, we can now build standardized tooling that can be used across all Ruby implementations and as a community start to develop a common language around how we discuss Ruby syntax trees. Going forward this could potentially mean all of the tools mentioned above could be running on the same underlying parser.
While we’re very happy about the technical win that this represents, we’re even more excited about the community win. With all of the excellent developers who have had to spend their time maintaining separate parsers now freed up, they can now invest that time in what makes their tools special. If they encounter errors with the parser, this means more eyes on the code, more people to help fix bugs, and more people to help add new features.
Performance
Once the parser was able to produce semantically equivalent syntax trees, we began looking at performance. We don’t have great comparison numbers yet because as discussed our tree is different and does more things in general (for example we provide unescaped versions of strings on our string nodes to make life easier on the consumers of YARP).
What we can share so far is that YARP is able to parse around 50,000 of Shopify’s Ruby files in about 4.49 seconds, with a peak memory footprint of 10.94 Mb. Needless to say, we’re thrilled with these results so far.
Going forward performance will be top of mind, and we have many optimizations we’ve been experimenting with. These include reducing memory usage through specialized tree nodes, improved locality through arena allocation, and faster identifier resolution with more performant hash lookups.
Integration
Once we got to a state where we could parse simple expressions, we wanted to validate our approach and design by integrating with other runtimes and tools.
JRuby and TruffleRuby teams began experimenting with the serialization API, and we worked with them to make sure it was sufficient for their needs. With some interesting tweaks (serializing variable width integers, providing a constant pool, and other optimizations) we found a format that suited their needs. Both runtimes now have invested significant energy in integrating YARP into their runtimes, and Oracle has someone working full time on making YARP TruffleRuby’s main parser.
We also worked with other tools to validate that our tree contained enough metadata for static analysis and compilation. Syntax Tree is a syntax tree tool suite that can also be used as a formatter, and it has an experimental branch running with YARP as its parser instead of Ripper. Early results show that by replacing Ripper with YARP, in some cases performance increased by nearly two fold. We also built a VSCode plugin that you can find inside the repository to ensure that our error locations and messages were correct, and work continues on that today.
Recently, we began experimenting with generating the same syntax tree as the parser and ruby_parser gems in order to seamlessly allow consumers of these libraries to benefit from the new parser. Early results are very promising and show both a reduction in memory and an increase in speed.
Finally, in the last week we have begun work on mirroring YARP into the CRuby repository, building it within CRuby, and running it within the same test suite and continuous integration. This is the final step before merging YARP into CRuby, and we’re very excited to see it come to fruition. This work will be done in the next couple of work days.
Path forward
This brings us to today and the path forward. Work continues on integrating YARP into all of the various Ruby runtimes, and we’re excited to try it out on more projects going forward (for example mruby and Sorbet). We’ll continue to work on speed, memory consumption, and accuracy. Matz and the CRuby team have agreed to ship YARP as a library with Ruby 3.3 (to be released this December), so in the next version of Ruby you will be able to require "yarp" and play around with your own syntax trees. A couple of things that will happen in the meantime before that exciting release:
- We will likely release the project as a gem, so that third-parties can begin working with it and integrating it into their own projects.
- We’ll continue to work with the JRuby and TruffleRuby teams to ensure that the structure of the syntax tree and the serialization API are sufficient for their needs. Hopefully soon we’ll get a release of these language runtimes that includes YARP as their main parser.
- Syntax Tree is going to adopt YARP as its main parser, which in turn means that ruby-lsp will reap all the benefits.
- We’ll continue to improve our compatibility with Ripper so that libraries that rely on that (admittedly unstable) API can use our compatibility layer as a means of migrating.
A lot more work is planned for the parser itself once it’s merged into CRuby. This includes, but is certainly not limited to:
- Forward scanning error tolerance - in places where the parser encounters syntax errors that could be interpreted in multiple ways, one approach is to parse with all possible interpretations forward by some number of tokens and then to accept the path that yields the least number of subsequent syntax errors
- Arena allocation - currently nodes are allocated with individual
malloccalls, which can be expensive and lead to fragmentation/a lack of memory locality - Memory usage - in general we have kept the tree relatively small in memory, but there is always room to take out any redundant information or generally reduce the size of the tree in memory
- Performance - obviously this is a massive topic, but now that we have reached parity with CRuby, we can start to look at ways to improve performance
Wrapping up
Overall, we’re very excited about this work and the future of Ruby tooling that it implies. We can’t wait to see what you build with it! If you have any questions this didn’t answer or are interested in contributing, please reach out to us on GitHub or Twitter!
Extras
For those of you that may want even more background or details, we’ve included some extra information below.
Background
A parser is the part of a programming language that reads source code and converts it into a format that can be understood by the runtime. At the high level, this involves creating a tree structure that represents the flow of the program. When you’re looking at source code you can often see this tree structure in the indentation of the code. For example, in the following code snippet:
def foo
bar
end
a def would be the top level node, containing various attributes like foo as a name. That node would have a statements as a child, which is a list of statements inside its body. The first statement would be a call node with bar as the method name.
The parser’s responsibility is to create these nodes and build the tree structure before handing it off to other parts of the programming language for execution. In the case of CRuby, the parser is responsible for generating the syntax tree that is then handed off to the YARV (Yet Another Ruby Virtual Machine) virtual machine for compilation. Once compiled, the generated bytecode is what is used for execution.
The first step to generating the tree is to break the source code into individual tokens, a process aptly called tokenization. In the case of Ruby, this means finding things like operators (~, +, **, ..., etc.), keywords (do, for, BEGIN, __FILE__, etc.), numbers (1, 0b01, 5.5e-5, etc.), and more. These tokens are evaluated lazily since they need large amounts of context to determine what they are (an identifier like foo can be a bare method call, a local variable, or sometimes even a symbol). You can think of this as a stream of tokens that the parser can pull from as it needs them.
The second step to generating the tree is to analyze the tokens by applying a grammar. A grammar is a set of rules that define how the tokens can be combined to form a valid program. For example, the grammar might say that a program can be a list of statements, and a statement can be a method definition, a method call, or a constant definition. The grammar can also specify the order in which the tokens can be combined. For example, a method definition can be a def keyword, followed by an identifier, followed by a list of arguments, followed by a body, followed by an end keyword. This is called a production rule.
Once the grammar has been applied and all of the ambiguities resolved, the tree is finally built. This tree is then handed off to the virtual machine for compilation and execution.
The parser that CRuby has used is generated by a tool called Bison, a parser generator that generates LR (left-to-right, rightmost derivation) parsers. Bison accepts a grammar file (in the CRuby codebase this is parse.y) and generates a parser in C (parse.c). Importantly, Bison requires the token stream we mentioned earlier. There are tools to generate these token streams, but CRuby has used a hand-written lexer. This lexer is responsible for tokenizing the source code and then providing the tokens to Bison as it needs them (through a function called yylex).
Challenges
Operators/keywords
The * operator can sometimes mean multiply and can sometimes mean splat, and sometimes it comes down to the number of spaces between the operator and the operand. Similarly ... can sometimes mean range and sometimes mean forward arguments. The do keyword can be used in a number of different contexts, including blocks (foo do end), lambdas (-> do end), and loops (while foo do end). Determining which operator or keyword to select depends on a number of different factors, none of which are documented.
Terminators
In Ruby, expressions can be separated by newlines, comments, or semicolons in almost all contexts, but not all. Lots of state is tracked to determine if a newline should be ignored or not. For example, in
{ bar:
1 }
the newlines are ignored and the 1 is associated with the bar: label, but in
def foo bar:
1
end
the newline after bar: is not ignored and the 1 is the only statement in the foo method.
Local variables
Because you can have method calls without parentheses, it can be difficult to determine if a given identifier is a local variable or a method call. For example,
a /b#/
can be interpreted as a method call to a with a regular expression argument, or as a local variable a divided by b. It depends on if a is a local variable or not (For more eccentricities like this, see a fascinating tric entry from 2022). Because of this ambiguity, a Ruby parser needs to perform local variable resolution as it is parsing.
Regular expressions
You would imagine that regular expressions would be easy to parse, because you can simply skip to the terminator. However, the terminator can be one of many characters. For example, you can write %r{foo}. In this case it’s not hard because you can find the next }, but unfortunately regular expressions (like the other % literals) actually balance their terminators. This means that %r{foo {}} is a valid regular expression because the parser keeps track of the number of { and } characters it has seen.
Regular expressions are also complicated by the fact that they can introduce local variables into the current scope. For example, /(?<foo>.*)/ =~ bar introduces a foo local variable into the current scope that contains a string matching the named capture group. This, combined with the local variable complexity above, meant that we additionally had to ship a regular expression parser in order to properly parse Ruby. (CRuby embeds the Onigmo parser which it happily delegates this work to, but again we didn’t want to ship with any external dependencies).
Encoding
CRuby by default assumes your source file is encoded using UTF-8 encoding, but you can change that by adding a magic comment to the top of the file. The parser is responsible for understanding those magic comments and then switching to using the new encoding for all subsequent identifiers. This is important for determining, for example, if something is a constant or a local which is encoding-dependent.
CRuby actually ships with 90 encodings (as of 3.3) that are both not dummy encodings and are “ASCII compatible” which means they can be used as an option for encoding source files. YARP ships with the most popular 23 of those encodings, with plans to support more as needed.