
Two Garbage Collection Improvements Made Our Storefronts 8% Faster
At Shopify, we are constantly working on improving the performance of Ruby for everyone. From YJIT, to Variable Width Allocation, to Object Shapes, we are making improvements to Ruby in many areas. One of our goals for the year is to analyze, tune and improve Ruby’s garbage collector for our largest and highest traffic apps. One of these apps is Storefront Renderer, which serves the storefronts of Shopify stores and is one of the highest traffic apps in the world. From analysis and experimentation on this app, we found two improvements in Ruby’s garbage collector that improved the average garbage collector performance by 46%, which translated to a decrease in average response time by 8% and 99th percentile response time by 25%.
These two changes will be released as part of Ruby 3.3, and could bring similar performance improvements to your app as well. In order to understand what they are and how they work, let’s take a closer look at these changes.
The REMEMBERED_WB_UNPROTECTED_OBJECTS_LIMIT_RATIO configuration
Feature #19571 added a new heuristic to the garbage collector that adjusts the upper limit of write barrier unprotected objects based on a ratio of the number of old objects. This ratio defaults to 1% and is adjustable via the RUBY_GC_HEAP_REMEMBERED_WB_UNPROTECTED_OBJECTS_LIMIT_RATIO environment variable.
To understand this feature, we first have to understand some important concepts in how Ruby’s garbage collector works. Ruby’s garbage collector is generational, meaning that it tracks how long an object has remained alive and will promote the object to the old generation after it survives for long enough. This allows the garbage collector to run minor garbage collection cycles, which do not scan old objects and so can significantly improve performance. A major garbage collection cycle scans all objects, which is much slower but has the opportunity to reclaim more objects in case any old objects have not survived. For this reason, we want to have as few major garbage collection cycles as possible. You can read about how the generation garbage collector works in more detail in my other blog post.
Another important concept to know is write barriers. Since minor garbage collection cycles do not look at old objects, any young object that is only referenced from an old object will not be marked by the garbage collector during a minor garbage collection cycle. This will appear to the garbage collector as if the young object has died and will be reclaimed by the garbage collector. This is a terrible bug because the old object still refers to the young object and if the Ruby program attempts to access the young object then it will crash. This problem is solved by the write barrier, which is a callback that lets the garbage collector know when an object is referenced by another object. If a reference is added from an old object to a young object, the write barrier is executed and the old object is placed in the “remember set”. The remember set is marked during all minor garbage collection cycles. Objects that support write barriers are known as “write barrier protected” while objects that don’t support write barriers are called “write barrier unprotected”. Write barrier unprotected objects cannot be marked as old, since doing so might lead to the bug mentioned earlier. Since these objects can never get old, they must be marked in every minor garbage collection cycle. You can read more details about write barriers in my other blog post.
Write barrier unprotected objects must be marked during every minor garbage collection cycle, but that slows down minor garbage collections. So, to improve performance, Ruby’s garbage collector has a heuristic to limit the maximum number of write barrier unprotected objects that can exist. When this limit is reached, a major garbage collection cycle is ran to try to reclaim these write barrier unprotected objects. This limit was calculated as a ratio of the number of write barrier unprotected objects that exist in the system (which default to 2, meaning the limit is twice the number of write barrier unprotected objects that exists after a garbage collection cycle). However, if very few write barrier unprotected objects survive a garbage collection cycle, it means that this limit becomes a fairly low value, which results in major garbage collection cycles being run frequently. In Storefront Renderer, we have tens of millions of old objects and only a few thousand write barrier unprotected objects. It’s extremely costly to scan tens of millions of objects in order to try to free a few thousand write barrier unprotected objects.
The RUBY_GC_HEAP_REMEMBERED_WB_UNPROTECTED_OBJECTS_LIMIT_RATIO adds a new heuristic to calculate the write barrier unprotected objects limit based on a ratio of the number of old objects. This means that even if we have very few write barrier unprotected objects, the limit will not be very low which reduces the frequency of major garbage collection cycles.
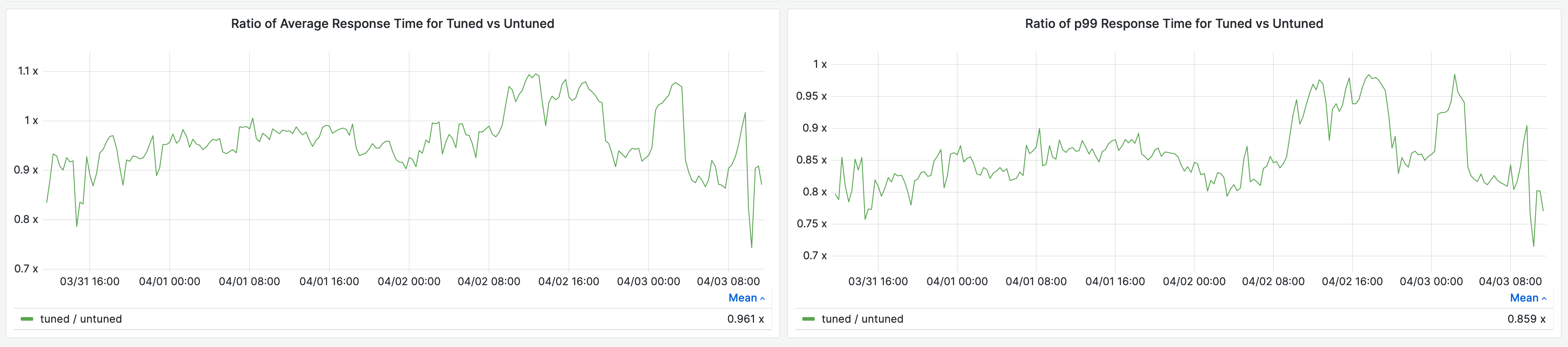
In the production environment of Storefront Renderer, we deployed this feature for a portion of traffic and saw a 33% reduction in average garbage collection time per request, and a 51% reduction in 99th percentile garbage collection time per request.
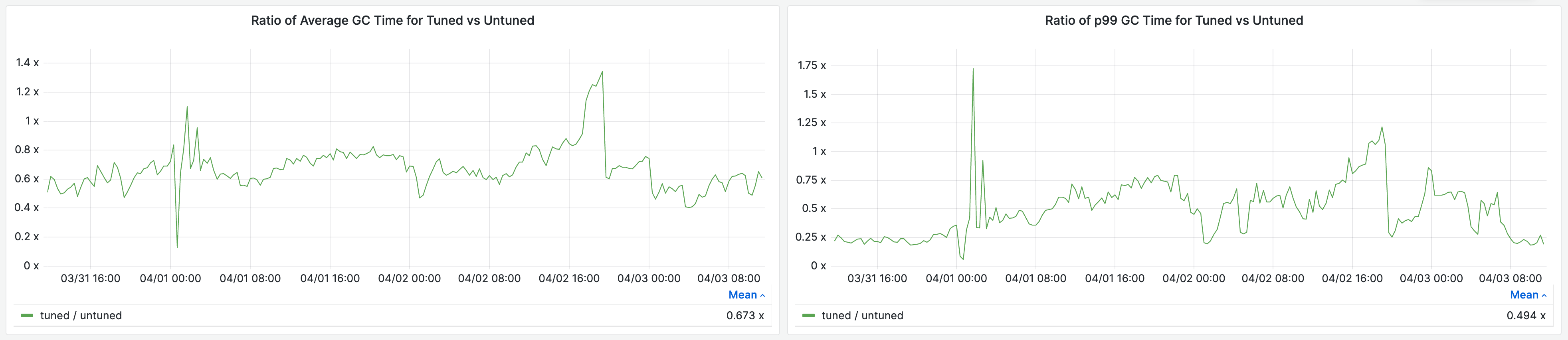
This reduced our average response time by 4% and 99th percentile response time by 14%.
Don’t immediately promote references of old objects
Feature #19678 changed the behaviour of the garbage collector’s object growth algorithm to not immediately promote young objects referenced from old objects. In the previous algorithm, if an old object referred to a young object, it would immediately promote the young object to the old generation (and in turn, all of the references of that young object will be promoted to the old generation). While this significantly reduces the amount of work in subsequent minor garbage collection cycles, it means that the young object (which is now an old object) will not be scanned in minor garbage collection cycles and will require a major garbage collection cycle to be reclaimed. In a web server, usually all objects that are allocated within a request do not survive much longer than the request, so ideally no objects created in the request are promoted to the old generation and we only run minor garbage collection cycles to collect the objects that were allocated in that request.
An example of an issue of the old algorithm is when a log entry is inserted to a temporary buffer. It’s likely that the buffer is an old object (since it will persist for as long as the lifetime of the application), so the log entry will be immediately promoted to the old generation. This means that even if the log entry is removed shortly after the insertion, it will remain alive until the next major garbage collection cycle. If we have millions of old objects in the system, a major garbage collection cycle can take several seconds.
This feature changed the algorithm so that if an old object refers to a young object, the old object will be placed in the remember set until the young object is either reclaimed by the garbage collector or survives for long enough so that it gets promoted to the old generation. Because all objects in the remember set is marked during every minor garbage collection cycle, this has the implication that it may increase the number of objects marked during minor garbage collection cycles, which may slow it down. The tradeoff is that there will be significantly less major garbage collection cycles ran if most of the young objects do not live for very long.
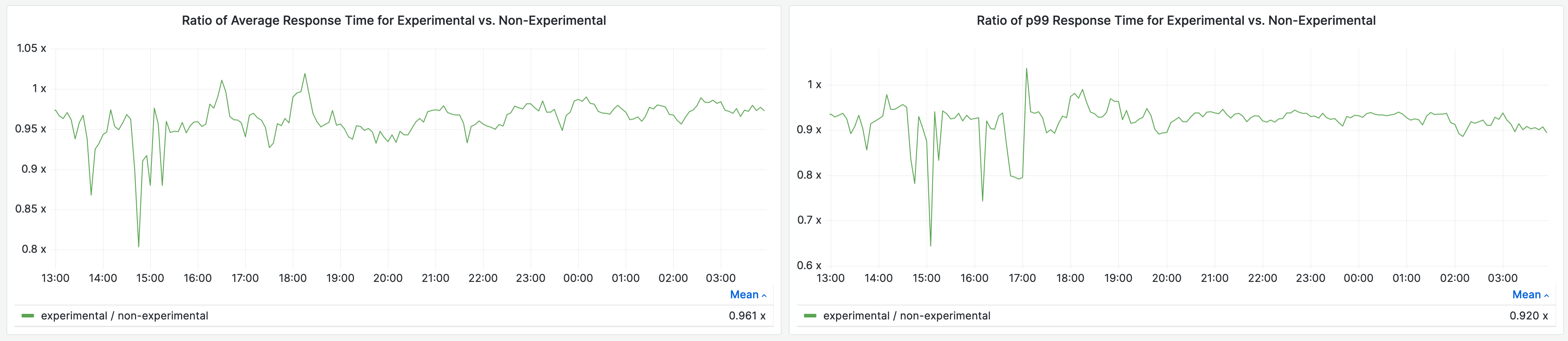
In the production environment of Storefront Renderer, we deployed this feature for a portion of traffic and saw 19% reduction in average garbage collection time per request, and a 12% reduction in 99th percentile garbage collection time per request.
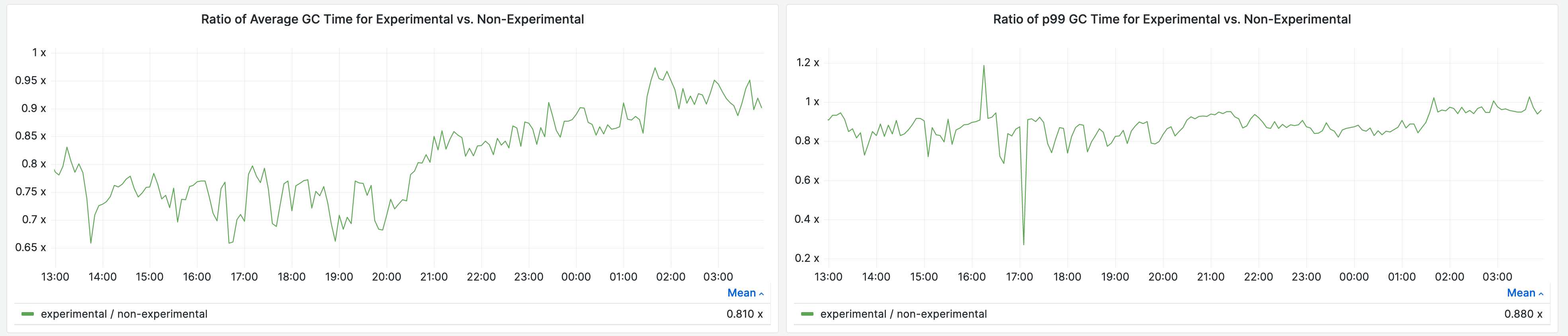
This reduced our average response time by 4% and 99th percentile response time by 8%.
Conclusion
By analyzing data from the garbage collection on our workloads, we were able to come up with two approaches that change different assumptions of the Ruby garbage collector. As a result, this allowed us to make our application run faster without changing any of its code. When doing performance work, it is always important to understand what’s causing the problem in the first place, and then to test out different approaches to address the identified problem. Solving these problems at the right level of abstraction allows us to deliver improvements not only for Shopify’s workloads but also to other applications that run on Ruby. If you are running a Ruby application, keep an eye out for all the improvements coming in Ruby 3.3 this Christmas.