
Ruby 3.3's YJIT: Faster While Using Less Memory
This year, the YJIT team has been working hard to improve and optimize YJIT. We’re proud to say that the version of YJIT to be included with Ruby 3.3 is leaps and bounds ahead of Ruby 3.2’s. It provides better performance across the board, while also warming up faster and using less memory. The 3.3 release is also more robust, including a number of bug fixes along with an improved test suite. In this blog post, we share some early numbers.
YJIT 3.3’s Optimizations
YJIT 3.3 includes several optimizations not present in 3.2. One of the main differences, performance-wise, is that we have much better JIT coverage. That is, there are much fewer situations where YJIT needs to fall back to the interpreter. In particular, YJIT is now able to better handle calls with splats as well as optional parameters, it’s able to compile exception handlers, and it can handle megamorphic call sites and instance variable accesses without falling back to the interpreter.
We’ve also implemented specialized inlined primitives for certain core
method calls such as Integer#!=, String#!=, Kernel#block_given?,
Kernel#is_a?, Kernel#instance_of?, Module#===, and more. It also inlines
trivial Ruby methods that only return a constant value such as #blank? and
specialized #present? from Rails.
These can now be used without needing to perform expensive method calls in
most cases.
Lastly, YJIT has a new register allocator which results in slightly
more efficient machine code.
In terms of reducing YJIT’s memory usage, this may be surprising to some, but the bulk of the memory used by YJIT is not taken by generated machine code, but rather by metadata YJIT uses to keep track of various pieces of information associated with said generated code. As such, we’ve spent a good amount of effort making multiple incremental improvements to cut down the size of the metadata that we keep.
Another key piece in terms of memory usage has been the introduction of a “cold threshold” heuristic. With this new heuristic, YJIT tries to cut down on the amount of “cold”, rarely used method that get compiled. This doesn’t make any difference on benchmarks, but it’s important for real-world production scenarios, because there is often a long tail of rarely used methods that get compiled, which keeps gradually increasing the size of the generated machine code, sometimes even multiple days after code has been deployed to production. With this heuristic, we’ve been able to cut down the size of the generated machine code and its associated metadata by about 20%. The key takeaway is, we’ve reduced memory usage not just by using less memory per piece of compiled code, but also by compiling less code in the first place.
Finally, this may or may not count as an optimization, but we’ve also made some changes to try and ship YJIT with better defaults out of the box. Following the 3.2 release, we’ve received feedback from multiple production deployments that it was necessary to adjust the YJIT configuration to change the memory size and call threshold values to get better performance. With YJIT 3.3, we’ve set default values that should work better for most production deployments. YJIT should now automatically increase the call threshold for any deployments that load more than a trivial amount of code, which should result in a smoother warm-up.
New Features in YJIT 3.3
YJIT 3.3 doesn’t just include performance improvements. We’ve also added some
new features to make your life easier. One such feature is that it’s now possible
to enable YJIT at run-time from Ruby code by calling RubyVM::YJIT.enable. This
makes it possible to selectively enable YJIT on some forked processes without
enabling it on all processes. It also makes it
possible to only enable YJIT after your app is done booting, so that you can
completely avoid compiling initialization code. The next Rails release will
take advantage of this to
automatically enable YJIT in an initializer.
We’ve also improved the way we collect run-time stats.
Prior to this, in order to collect performance statistics, you needed to
rebuild Ruby from source to produce a special stats build. Most end users found
this inconvenient, particularly in a production environment. Most of the stats
provided by --yjit-stats are now available in release builds. This will make
troubleshooting performance issues easier.
Please note here that we are talking about statistics for you to consult about
your programs. For security and privacy reasons, YJIT does not “phone home”.
Another recent addition is a new --yjit-perf command-line option which
enables profiling with Linux perf by setting up frame pointers for YJIT
frames and producing a perf map.
More details about new additions to YJIT and Ruby 3.3 are provided in
the release notes for Ruby 3.3.0-rc1.
Performance on benchmarks
We’ve benchmarked YJIT using the headline benchmarks from the yjit-bench suite. These are benchmarks based on real-world gems which aim to be representative of real-world use cases, with a bias towards things that we believe represent typical web workloads. The graph below shows a comparison of the performance of the Ruby 3.2 interpreter, Ruby 3.3 interpreter, Ruby 3.2 + YJIT, and Ruby 3.3 + YJIT. The benchmarks were run on a Ryzen 7 3700X machine running Ubuntu Linux 22.04. Higher is better, with bars being normalized to 1.0 for the performance of the Ruby 3.2 interpreter. For these experiments, we used a bleeding edge commit directly from the Ruby/master branch of the git repository.
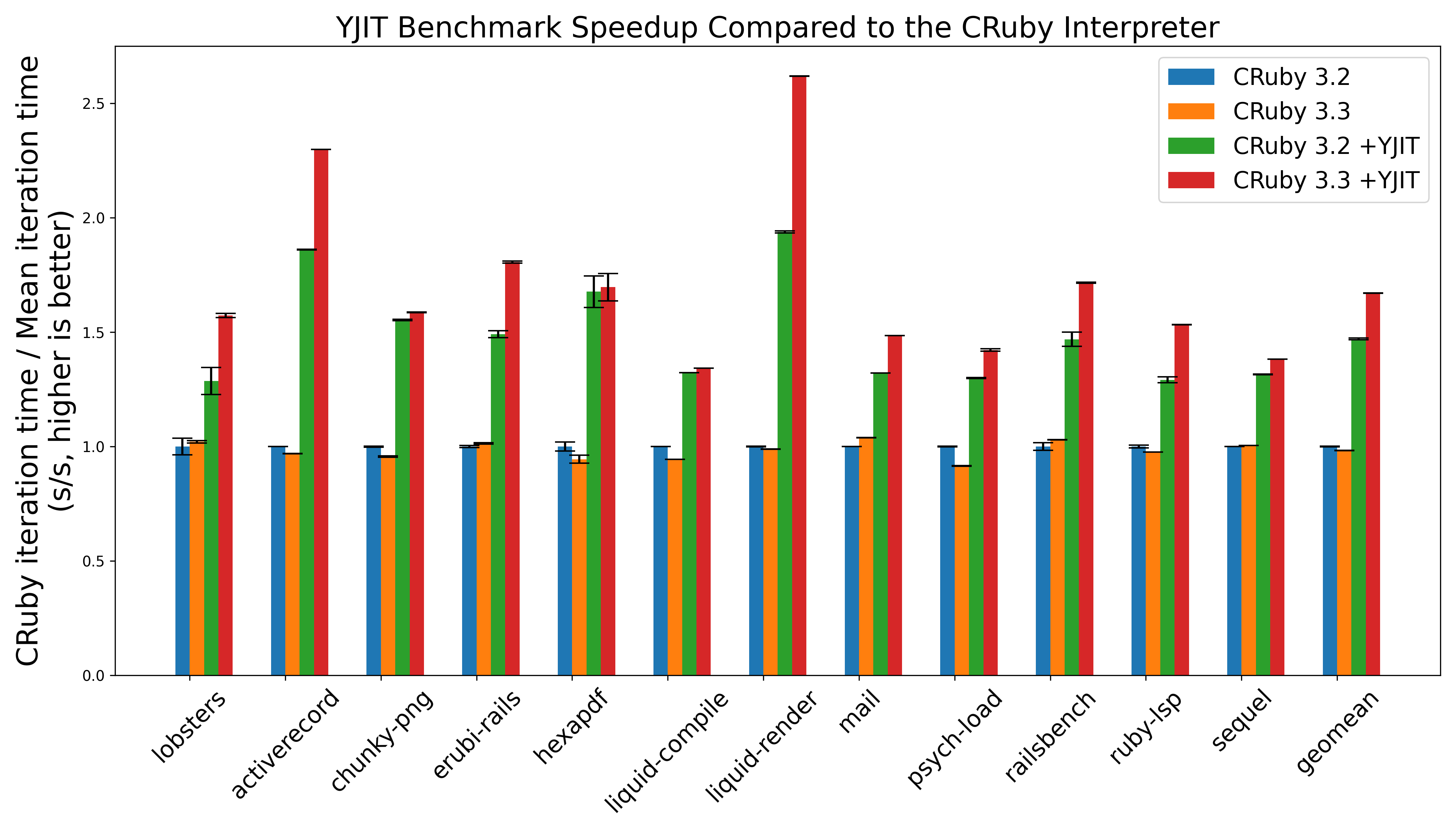
As you can see, YJIT 3.3 delivers a performance boost over YJIT 3.2 on every benchmark, and the difference is usually quite significant. Notably, rendering liquid templates is now over 2.5x faster with YJIT enabled than it is using only the Ruby 3.2 interpreter. Railsbench is about 65% faster with YJIT. We’ve turned the lobste.rs website into a benchmark, which we can render over 50% faster with YJIT as well, and if you’re using the Ruby LSP language server in your code editor, YJIT also provides a 50%+ performance boost there too.
Memory usage on benchmarks
JIT compilers typically come with a tradeoff, which is that to some extent, they’re trading slightly increased memory usage for better performance. As outlined previously, we’ve done a lot to reduce the amount of memory overhead YJIT incurs. The overhead is still nonzero, but it has been much improved, to the extent that it’s no longer an issue for our production deployments at Shopify.
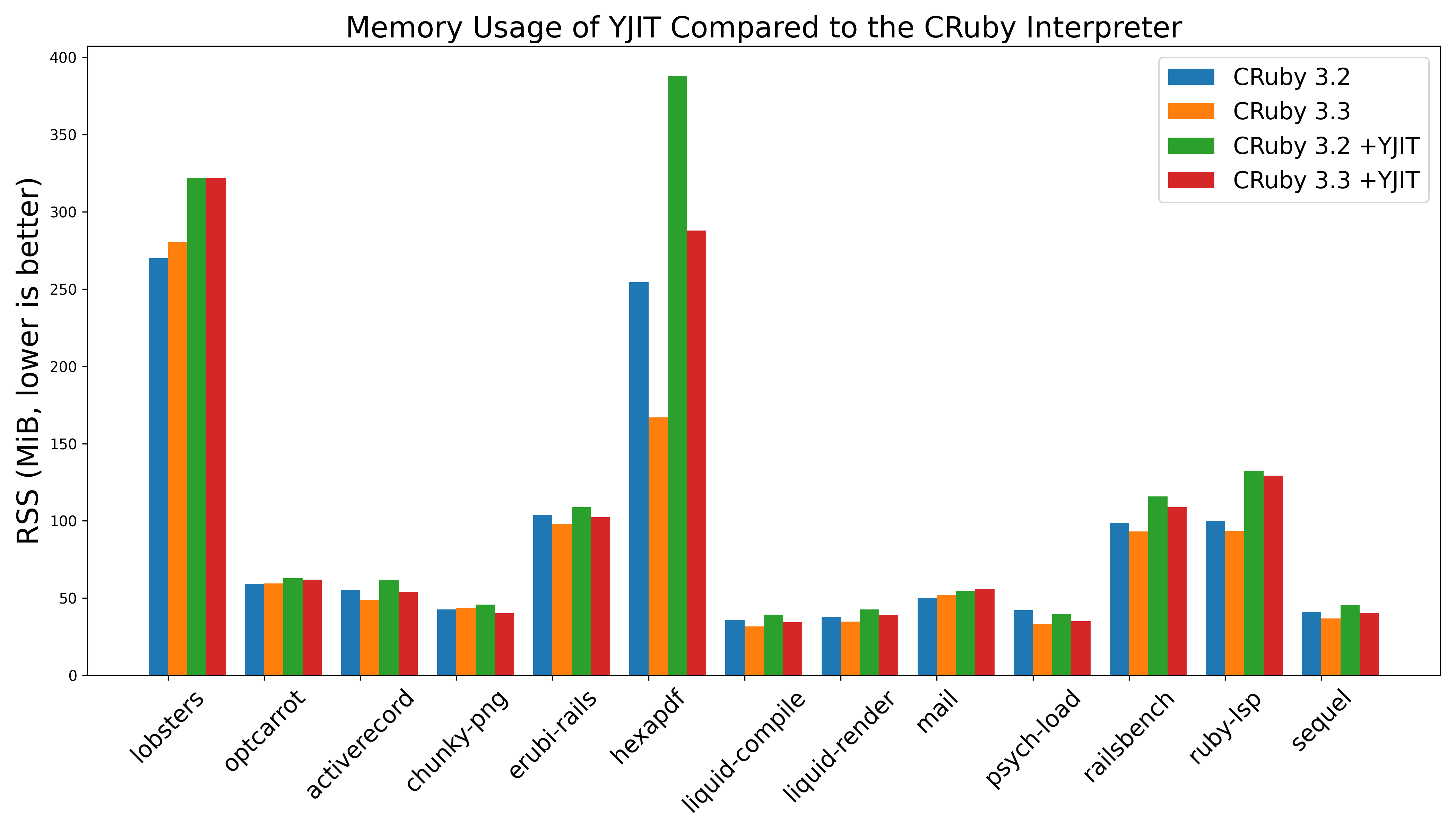
The graph above shows the memory usage on each of our benchmarks running with and without YJIT enabled for both Ruby 3.2.2 and 3.3.0. The great news is that the memory usage for YJIT 3.3 is below that of YJIT 3.2 on almost every benchmark. Part of this reduction in memory usage is due to the work the YJIT team put in to use memory more effectively. YJIT executes a higher percentage of total YARV instructions than before, it generates more machine code per Ruby method compiled, and manages to do this with less total overhead.
However, much of the credit for the reduced total memory usage goes to my colleagues Peter Zhu and Matthew Valentine-House. They’ve done some great work on the Ruby Garbage Collector (GC) to improve its performance and reduce CRuby’s memory usage. You can see this in the above graphs too. It’s not just YJIT’s memory usage that went down. The memory usage of the CRuby 3.3.0 interpreter is below that of the 3.2.2 interpreter for most benchmarks.
In the spirit of transparency, we note that in the graph above, there is an anomaly, which is that YJIT’s
memory overhead on the hexapdf benchmark is much higher than on other benchmarks. This is something
we’ve discovered as we were producing graphs for this blog post, and are currently investigating. As far
as we can tell so far, it seems to be an issue caused by glibc’s malloc not releasing memory to the
operating system often enough in the presence of mmap calls. Manually calling malloc_trim(3) or
using jemalloc seems to fix the issue.
SFR Production Deployment
YJIT has been deployed to all of Shopify’s StoreFront Renderer (SFR) infrastructure for all of 2023. For context, SFR renders all Shopify storefronts, which is the first thing buyers see when they navigate to a store hosted by Shopify. It is mostly written in Ruby, depends on over 220 Ruby gems, renders millions of Shopify stores in over 175 countries, and is served by multiple clusters distributed worldwide. We’ve deployed Ruby 3.2.2 and 3.3.0 (Ruby master) to experimental clusters (a subset of SFR servers) so we could gather experimental data for this blog post.
Performance: YJIT 3.3 vs the CRuby 3.3 Interpreter
The following graph is a snapshot from our dashboard comparing the performance of the Ruby 3.3.0 interpreter vs YJIT 3.3.0 over the last 12 hours. The speedup figures that we see tend to change over time depending on web traffic, but we believe it’s representative of the kinds of speedups you can hope to get from YJIT 3.3. The Y-axis shows the speedup YJIT provides compared to the interpreter. This is computed based on the total end-to-end time needed to generate a response, including time the SFR servers spend doing I/O, waiting on databases, and other operations YJIT cannot optimize. As we can see, the amount of speed boost that YJIT provides over the interpreter changes depending on time of day and web traffic, but YJIT is consistently faster than the interpreter on average, even on the p99 slowest requests. This is great, because speeding up the slowest requests makes the most difference to user experience.
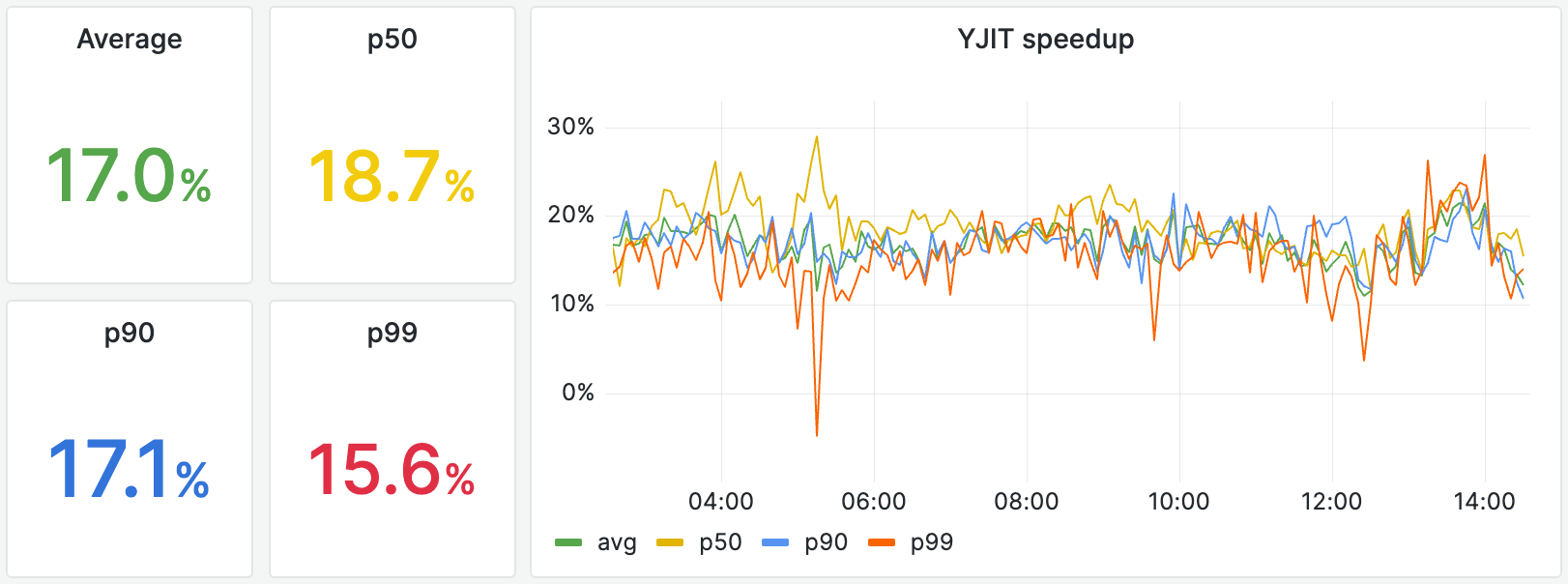
YJIT 3.3 is generally quite a bit faster than YJIT 3.2 on average. The difference is especially marked on the p99 slowest requests. This is likely because of targeted optimizations made to reduce the time YJIT takes to generate code, as well as the addition of a “cold threshold” heuristic to reduce the long tail of code that YJIT compiles. That is, YJIT 3.3 is more selective about which Ruby code it optimizes.
Memory usage: YJIT 3.3 vs the CRuby 3.3 Interpreter
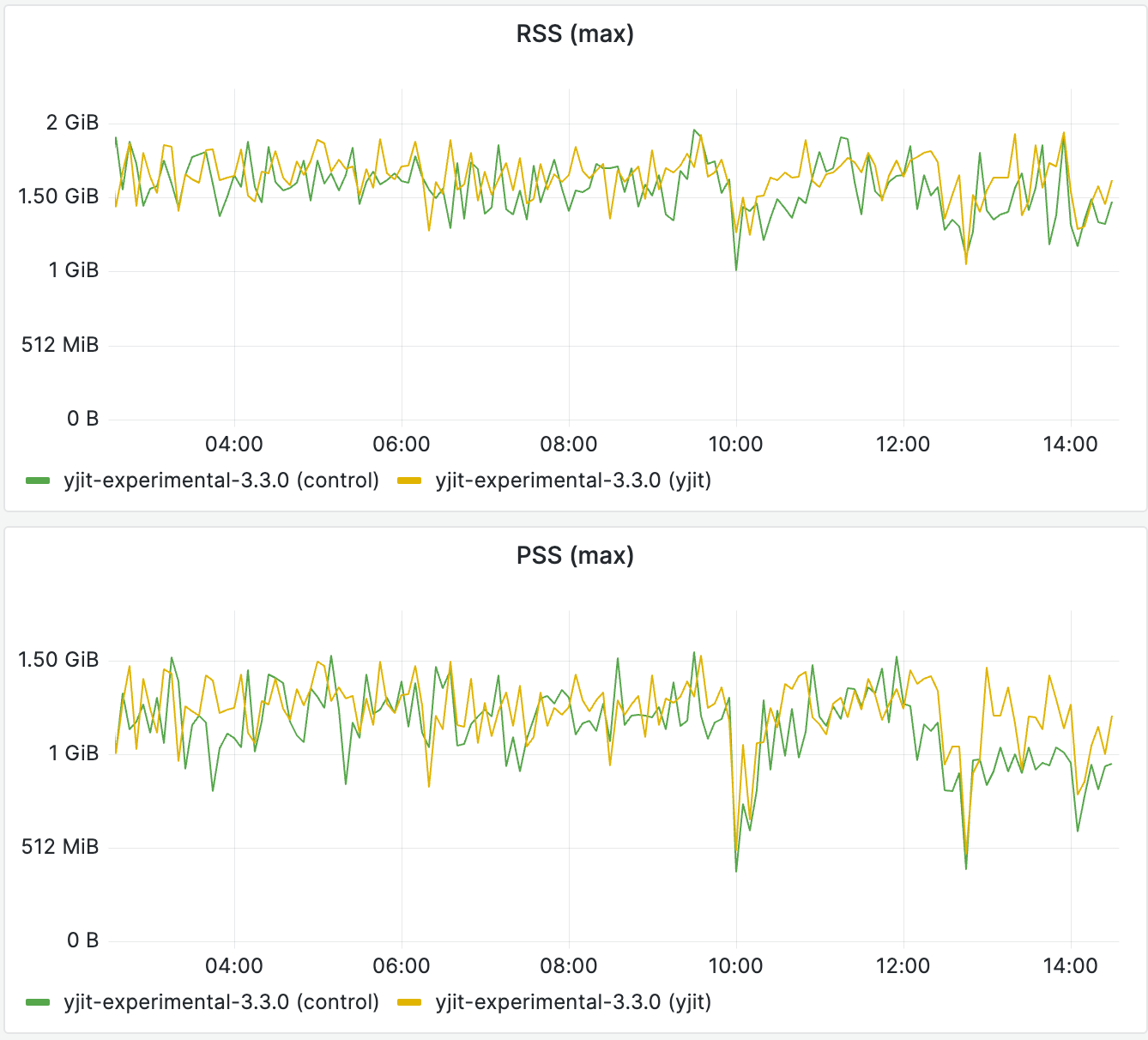
The graph above shows the RSS (Resident Set Size) and PSS (Proportional Set Size) of processes running YJIT 3.3 vs the CRuby 3.3 interpreter over the last 12 hours. When looking at the PSS, which takes into consideration memory shared between multiple server processes with Unicorn, the memory overhead of enabling YJIT is currently below 8% for our SFR deployment, which we deem to be a good memory vs performance tradeoff.
Optcarrot and Ruby3x3
At RubyConf 2015, Yukihiro Matsumoto (aka Matz), chief designer of the Ruby programming language, announced Ruby3x3, the goal of making Ruby 3 three times faster than Ruby 2. He compared this objective to John F. Kennedy’s goal of landing humans on the moon within the decade. Despite the lack of concrete plans to achieve this, Matz stated that a JIT compiler may be useful in achieving his inspiring objective.
The optcarrot benchmark is not one that we look at often at Shopify, because we don’t consider it to be representative of web workloads, or the workloads that the majority of Ruby users typically run. This benchmark is a NES emulator. It implements its own interpreter loop, and contains multiple large methods that perform a lot of bitwise arithmetic, which is something that is almost nonexistent in web software. However, NES emulators will always be cool, and as self-respecting programmers, we have a moral duty to ensure that Ruby can make them run fast, akin to the hippocratic oath sworn by doctors.
In December of 2020, Takashi Kokubun’s MJIT achieved a significant milestone by showing that it could run optcarrot
more than 3 times faster than Ruby 2.0, thereby achieving the Ruby3x3 goal (as long as you accept
performance on optcarrot to be a representative metric of Ruby’s performance).
Today, with the imminent release of YJIT 3.3, we can proudly say that Ruby 3.3 is over 3.3 times
faster than the CRuby 3.3 interpreter on this benchmark, thereby hitting a new major milestone, which
we have coined post-hoc as Ruby3.3x3.3.
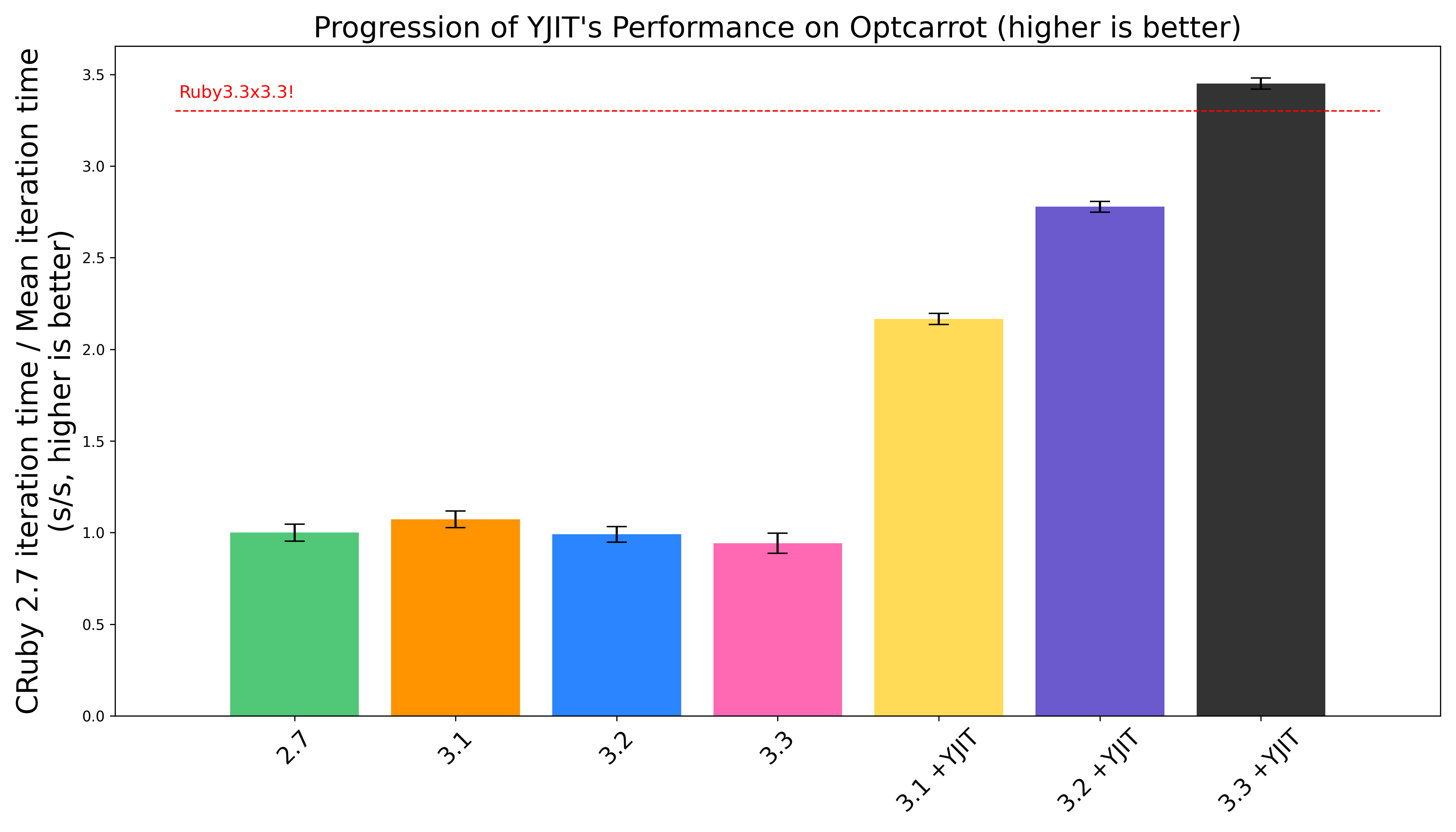
As can be seen in the graph above, performance on optcarrot has gone up markedly with every new
YJIT release. According to stats produced by --yjit-stats, YJIT now executes more
than 99.1% of the instructions in this benchmark, and is also able to inline 79.9% of C function calls,
most of which are calls to Ruby runtime functions which YJIT is able to optimize. We hope to be able
to deliver even better performance for Ruby NES emulators next year.
Conclusion
The Ruby 3.3.0 release will be available for you to download on ruby-lang.org on December 25th. In the mean time, if you’re feeling really impatient to play with Ruby 3.3, you can find the latest release candidate along with its release notes on the Ruby releases page. With this release comes a much more capable version of YJIT, with multiple major improvements. The bottom line is that YJIT performs better, while using memory more efficiently and warming up faster.
If you’re interested in learning more about YJIT, we’ve published a paper at the MPLR 2023 conference, which is now freely available through ACM open access. A video recording of our presentation at MPLR is also available on YouTube. There are also multiple presentations about YJIT available on YouTube, ranging from very approachable to deeply technical.
Lastly, I’d like to give a big thanks to Shopify, Ruby & Rails Infrastructure and the YJIT team for making this project possible. Thank you Aaron Patterson for helping me put together this blog post. A special shout out goes to Alan Wu and Takashi Kokubun. Two incredibly talented programmers that I have the privilege to work with on the YJIT project. They’ve worked tirelessly to make the Ruby 3.3 release as performant and stable as possible. If you’re using YJIT in production, please give us a shout out on Twitter/X. It’s always very rewarding for us to hear about YJIT being deployed in the wild!